

Once you’ve run machine learning models in production, reproducibility becomes one of the non-negotiable aspects of delivery since the baseline performance of the model has already been defined. The ability to replicate results, debug issues, and improve models requires that all experiments are easily traceable. Unlike traditional software development, where versioning source code is sufficient to reproduce builds, ML workflows can degrade significantly with changes to the data, its distribution as well as changes to any preprocessing steps.
In this article, we’ll explore what data versioning entails, the challenges it addresses, and how it can be easily integrated into your ML workflow.
How is data versioning different?
The aspects of the right side of the diagram look very similar to packaging a service:
Code changes: If you run into any issues, you can rollback your code so that it continues to function as before.
Experimentation: You can experiment with different variants by using a feature toggle.
CI pipeline: Individual stages of the pipeline e.g. test/build/promote have not been displayed in the image above.
Things that are different:
Training pipeline: The artifact in an ML project is heavily influenced by the code, configuration and data. Changes to any of them affect the model weights and hence prediction accuracy significantly. In certain cases, the model may no longer be relevant if the data changes significantly.
Experimentation: Depending on the complexity and desired accuracy of the problem, the experimentation cycle can even go on for several months. Through this window, it is essential to be able to identify the best model. Managing this effectively in a wiki/document is not sustainable since different types of changes are involved:
Code changes: Apply different pre-processing steps
Configuration changes: Experiments done with combinations of hyper-parameters
Data: The distribution of the data, its schema and more can all change over time.
Metric tracking: Data quality metrics and any evaluation metrics can be tracked via data versioning so that there is full traceability.
Collaboration: The complexities associated with collaboration over code have mostly been solved by Git and other version control tools. Data and configuration add additional layers to the problem since the traceability of an artifact, its accuracy and the corresponding data/config becomes a challenge.
Data versioning solves these problems by providing capabilities similar to git:
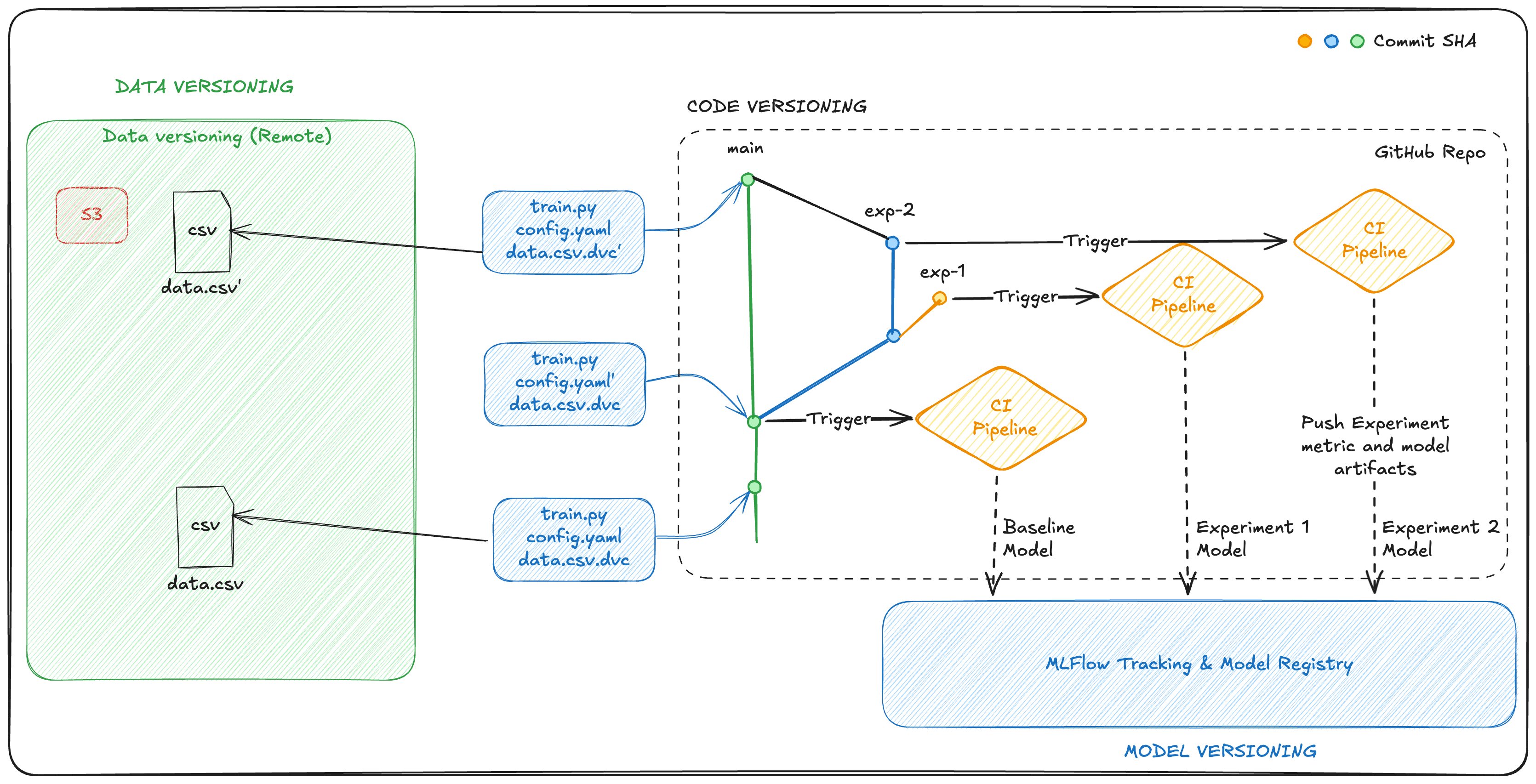
Versioning of data: Versioning of the raw, processed and intermediate datasets and corresponding model outputs ensures that you get a fully reproducible environment inclusive of the data, model and its outputs by reverting to a specific data version commit.
Leverage metadata for context: The input datasets, the code and the config parameters and the output need to be linked together for each run of an experiment. This provides full traceability and reproducibility of the results
Storage strategies: The code repository only has a reference to a commit/ref of the data version repository. The actual files are centrally managed on object stores like S3/GCS.
Lifecycle with data versioning
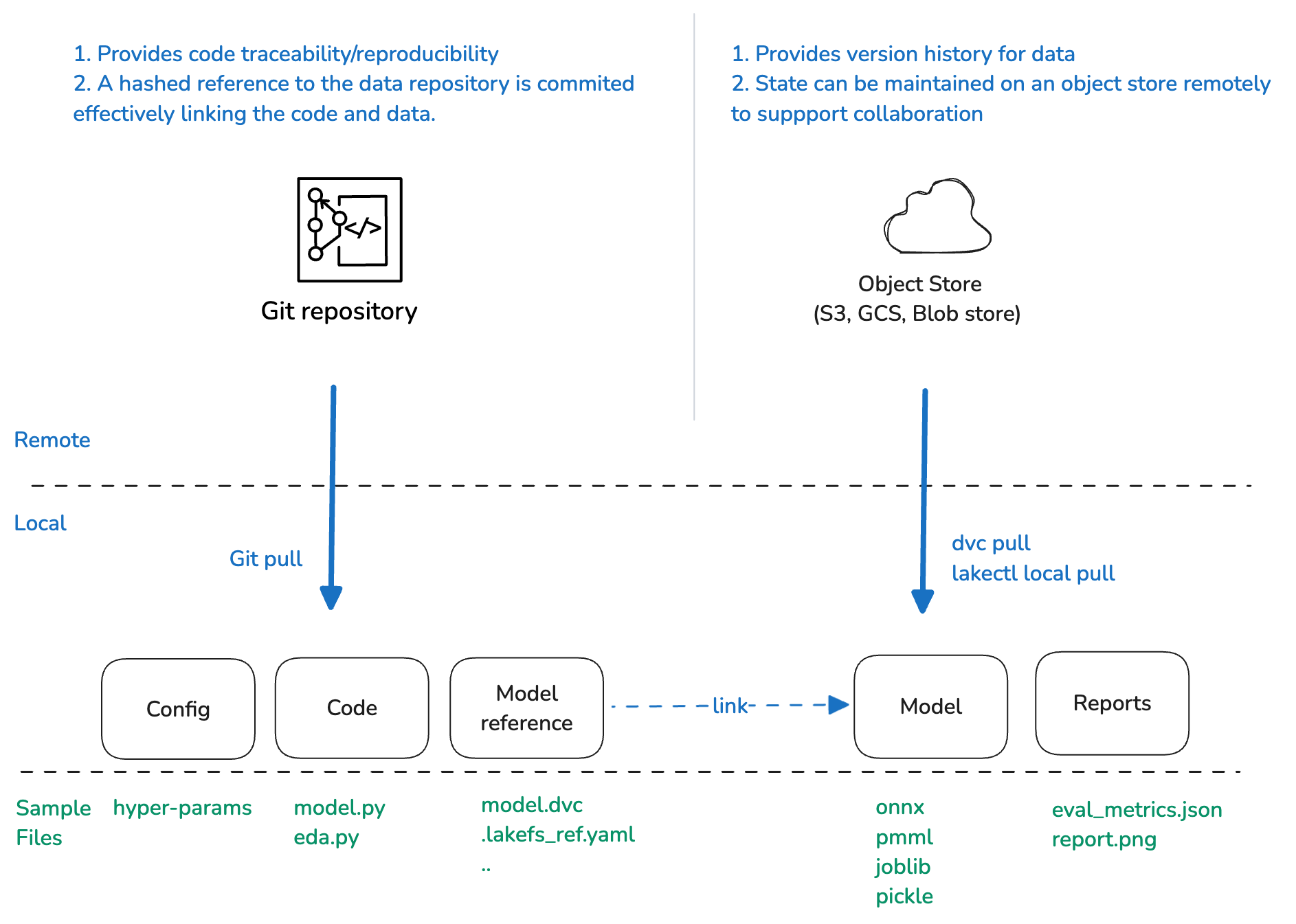
Tool considerations
Popular tools in this space include DVC, GitLFS, doIt, LakeFS. These tools provide an excellent interface over hand-rolling your own tooling over object stores like S3/GCS. Choosing an appropriate tool requires one to think about a few aspects:
Dataset size: With larger datasets, depending on the underlying storage representation, the data storage requirements may grow multi-fold and some tools do not handle this effectively. Appropriate data retention policies should be set up so that unreferenced data can be safely removed.
Team collaboration: Multiple individuals may work on the same problem statement requiring close collaboration and effective merge resolution strategies.
Access control: Access control and auditing capabilities are required for sensitive datasets like financial and PII datasets.
Tool Integration: Integration with other systems like Experimentation (MLFlow / Kubeflow etc), visualisation of run metrics, model packaging etc. ensures that the corresponding artifacts in third-party systems can be mapped to specific
Infrastructure: Tools like DVC have a smaller infrastructure imprint. Others like LakeFS require a database to manage the metadata (branch information, commit history etc).

Neptune, Dagshub, Deepchecks, and LakeFS have done detailed comparisons. Please be aware that this is a rapidly evolving space and the examples and references given here are only meant to provide you with an idea.
Conclusion
Data versioning plays a key role in building reliable, reproducible, and scalable machine learning systems. By tracking changes to datasets and associating them with experiments and model versions, teams can streamline their development cycles and bring in auditability and traceability. Validating the capabilities of data versioning on small, critical datasets can help teams validate and benefit from its capabilities.
Thanks to Ajinkya, Jaju, Rhushikesh and Swapnil for reviewing early drafts and providing detailed feedback. Ajinkya, Harshad, PV, Preethi and Sanket for building internal ML accelerators and sharing their experiences with these tools.

