
Introduction
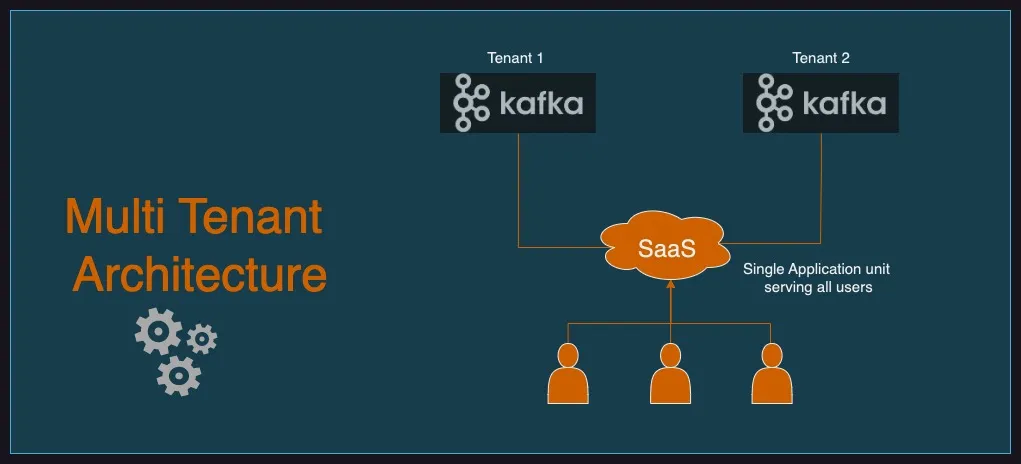
In modern SaaS applications, Apache Kafka is a powerful tool for processing massive volumes of real-time data. But as you scale, especially in a multi-tenant architecture, challenges begin to surface—particularly around Kafka cluster management and consumer design.
This blog walks you through how to build a multi-tenant Kafka consumer in Spring Boot, allowing a single application instance to consume messages from multiple Kafka clusters—each dedicated to a tenant group. It also covers writing multi-tenant aware Kafka producer.
The Problem
You’re building a SaaS application that relies heavily on Kafka to handle large-scale streaming data. To scale efficiently:
You may decide to split your Kafka infrastructure into multiple clusters or groups—each serving a different set of tenants.
You may create topics per tenant, to maintain the tenant isolation.
Now, the next question arises: How do you deploy application instances to support multiple Kafka clusters while minimizing operational complexity?
Why “One App per Tenant Group” Doesn’t Scale
One naive solution is to deploy a separate instance of your application for each tenant/group of tenants, with each configured to use a different Kafka cluster. While this technically works, it becomes problematic at scale.
Here’s why:
Operational Overhead: Managing dozens or even hundreds of application instances introduces significant DevOps complexity:
You’ll need to maintain separate deployments, configurations, and monitoring for each tenant group.
CI/CD pipelines become more complex as you must parameterize builds for each tenant group.
Troubleshooting or rolling out fixes means repeating the process N times—once for every instance.
Resource Inefficiency: Each application instance consumes memory, CPU, and possibly a dedicated container or VM:
This leads to underutilization of system resources, especially for a low-traffic tenant group.
Scaling infrastructure per tenant group can lead to increased cloud costs.
Limited Flexibility:
If you decide to create a separate cluster for serving some of the tenants then you need to deploy one more app instance.
Making global changes (e.g., security patches, feature updates) requires coordinating updates across all instances.
Increased Risk of Drift:
With many per-tenant deployments, it’s easy for configurations to drift over time.
This can lead to inconsistent behavior across tenants and make debugging more difficult.
The Better Way: Application-Level Multi-Tenancy
Instead of creating multiple app instances, you can design your application to support multi-tenancy internally. This approach allows a single application instance to dynamically connect to different Kafka clusters based on the configuration.
Benefits of this design:
Flexibility: With appropriate planning you can migrate tenants from one cluster to another. And single application lets you connect to multiple clusters seamlessly.
Operational Efficiency: Reduces the overhead of managing and deploying multiple instances per tenant group.
Approach
Let’s build the solution step by step. We first need to build the tenant configuration and then we will build tenant-aware Kafka consumers.
Tenant Configuration
The application.yml file holds the configuration settings for the Kafka multi-tenant application. It defines a collection of Kafka clusters, each associated with its own set of bootstrap servers and a list of tenants.
Same pattern can be used to handle multi tenancy with respect to other tools like databases, AWS accounts, etc.
This approach ensures that the system can handle tenant-specific requirements efficiently while maintaining high availability and scalability.
tenant-config:
groups:
group1:
kafka:
bootstrap-server: localhost:9092
tenants:
- test-tenant1
group2:
kafka:
bootstrap-server: localhost:9092
tenants:
- test-tenant2Dynamic Consumer Creation with Spring Kafka
To support multi-tenant groups, we create dedicated Kafka consumers based on group-specific tenant configuration. A key design goal is to leverage Spring Kafka’s annotation-based support @KafkaListener as much as possible rather than falling back to a fully programmatic listener setup.
Why avoid the programmatic approach?
It introduces unnecessary complexity.
Features like Kafka retries and error handling need to be wired manually.
You lose the expressive simplicity and auto configuration benefits provided by Spring.
To retain the power of annotations while allowing dynamic configuration, we use Spring’s ConfigurableListableBeanFactory to manually register Kafka consumer beans at runtime. This allows us to still take full advantage of the @KafkaListener annotation.
Example Code Snippet
@Bean
public List<KafkaConsumer> kafkaConsumers(@Autowired final TenantConfig tenantConfig,
@Autowired final ConfigurableListableBeanFactory beanFactory) {
return tenantConfig
.groups()
.values()
.stream()
.flatMap(group -> buildKafkaConsumers(beanFactory, group.kafka()))
.toList();
}
private Stream<KafkaConsumer> buildKafkaConsumers(final ConfigurableListableBeanFactory beanFactory,
final TenantConfig.GroupConfig.KafkaConfig kafkaConfig) {
return kafkaConfig
.tenants()
.stream()
.map(tenantId -> {
var containerFactory = containerFactory(kafkaConfig.bootstrapServer());
String topicName = buildTopicName(tenantId);
String groupId = "group-" + tenantId;
KafkaConsumer kafkaConsumer = new KafkaConsumer(topicName, groupId, containerFactory);
beanFactory.initializeBean(kafkaConsumer, "KafkaConsumer" + topicName);
return kafkaConsumer;
});
}But there’s a challenge: How do we pass tenant-specific values like topic, group ID and container factory to the @KafkaListenerat runtime?
We solve this using Spring Expression Language (SpEL) inside the annotation. Here’s what the consumer looks like:
public record KafkaConsumer(String topic, String groupId, ConcurrentKafkaListenerContainerFactory<String, String> factory) {
@RetryableTopic(
backoff = @Backoff(delay = 2000),
dltTopicSuffix = ".dlt")
@KafkaListener(topics = "#{__listener.topic}", groupId = "#{__listener.groupId}", containerFactory = "#{__listener.factory}")
public void listen(String message, @Header(RECEIVED_TOPIC) String topic) {
//implementation
}
}Why is this powerful?
Retains simplicity of annotation-based listeners
Fully tenant aware
No custom retry logic needed
Dynamic Producer Creation
Just like consumers, we dynamically manage Kafka producers per tenant.
Key Points
Each tenant gets a separate
KafkaTemplateinstanceThese templates are created on demand and cached
Messages are routed to the appropriate topic using the tenant ID
Example Code Snippet
@Component
public class KafkaProducer {
private final TenantConfig tenantConfig;
private final Map<String, KafkaTemplate<String, String>> kafkaTemplates = new ConcurrentHashMap<>();
public KafkaProducer(TenantConfig tenantConfig) {
this.tenantConfig = tenantConfig;
}
public void publish(final String tenantId, final String message) {
kafkaTemplates.computeIfAbsent(tenantId, this::createKafkaTemplate).send(getTopicForTenant(tenantId), message);
}
private KafkaTemplate<String, String> createKafkaTemplate(final String tenantId) {
Map<String, Object> producerProps = new HashMap<>();
producerProps.put(BOOTSTRAP_SERVERS_CONFIG, getBootstrapServerForTenant(tenantId));
producerProps.put(KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
producerProps.put(VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
producerProps.put(CLIENT_ID_CONFIG, "producer-" + tenantId);
ProducerFactory<String, String> producerFactory = new DefaultKafkaProducerFactory<>(producerProps);
return new KafkaTemplate<>(producerFactory);
}
private String getBootstrapServerForTenant(final String tenantId) {
return tenantConfig.groups().values().stream()
.filter(config -> config.kafka().tenants().contains(tenantId))
.findFirst()
.map(config -> config.kafka().bootstrapServer())
.orElseThrow(
() -> new IllegalArgumentException("Tenant " + tenantId + " not supported"));
}
private String getTopicForTenant(String tenantId) {
// Logic for mapping tenantId to topic
return tenantId + "-output-topic";
}
}That’s it! This is how you can build a fully multi-tenant aware Spring Boot application. This design gives us the best of both worlds: the flexibility of dynamic configuration and the ease of use that comes with Spring’s annotation-driven Kafka support. It also helps you avoid operation complexities that come along with “One App per Tenant Group” approach.
Resources
About the Author
I’m a Software Architect passionate about building scalable platforms and data architectures. If this article helped you then feel free to share it or ⭐️ the repo!
Review Credits
Thanks Rhushi, Mohit, Karun, Prashant for reviewing this post and providing valuable feedback.

