


The Background
The healthcare industry is bogged down with complex, time-consuming paperwork and tasks, and often the standard Electronic Medical Records (EMR) systems are part of the problem. That’s why we embarked on Project xEMR to build an AI-augmented EMR Extension platform. The purpose was to dramatically cut the administrative work for medical staff. Project xEMR is an AI layer that sits on top of existing EMR systems. It doesn’t replace them; it only makes them smarter. It strictly follows essential healthcare standards like FHIR R4 and SNOMED CT, ensuring the data is completely secure and clinically accurate.
Document Intelligence: It can read and summarize documents, no matter the file format.
Clinical Data Extraction: It automatically pulls out key clinical data.
FHIR R4 and SNOMED CT Compliance: It helps write documents like treatment plans and discharge papers.
Beyond creating a product, we intended to revolutionize the software development lifecycle. Our two main goals were:
Change the way we build: We aimed to create a new engineering culture where we build an AI-Powered EMR system primarily using AI Agents (Agentic AI Workflows), with human developers only focusing on the most critical parts, thereby creating minimal traditional human-made work (artifacts).
Create a Blueprint for the Future: We wanted to prove and create a repeatable model for these AI workflows that could transform the entire development process, from the initial research phase to the final deployment, by systematically applying AI help during the Explore, Plan, and Implement stages.
Project xEMR showcases a modern, AI-first approach to software development, utilizing agentic workflows throughout exploration, planning, architecture design, and implementation phases.
The Business Challenge
Building this system was difficult because we had to meet several high-level technical and operational standards:
Strict Healthcare Rules: The system had to follow mandatory healthcare industry standards, specifically FHIR R4 and SNOMED CT, to ensure clinical data is accurate and can easily be shared with other medical systems.
Sophisticated Design: We used advanced design strategies (DDD, CQRS, Event-Driven) to manage the complexity and make sure the system is powerful, organized, and ready to scale. We built it as a Modular Monolith—a single structure with distinct, organized parts.
Modern Technology: The entire application was built using a cutting-edge stack: the backend used Modern Python with the FastAPI framework, and the frontend was built with Next.js 15 and TypeScript.
Built for the Cloud: The entire application was designed from the ground up for AWS, using Fargate ECS (a serverless computing engine) to ensure deployment is scalable, automated, and modern.
Guaranteed Quality: We put a comprehensive testing strategy in place, using tools like pytest (for the backend) and Vitest (for the frontend), to maintain high clinical accuracy and code quality throughout the project.
The ‘intelligent Engineering’ Solution
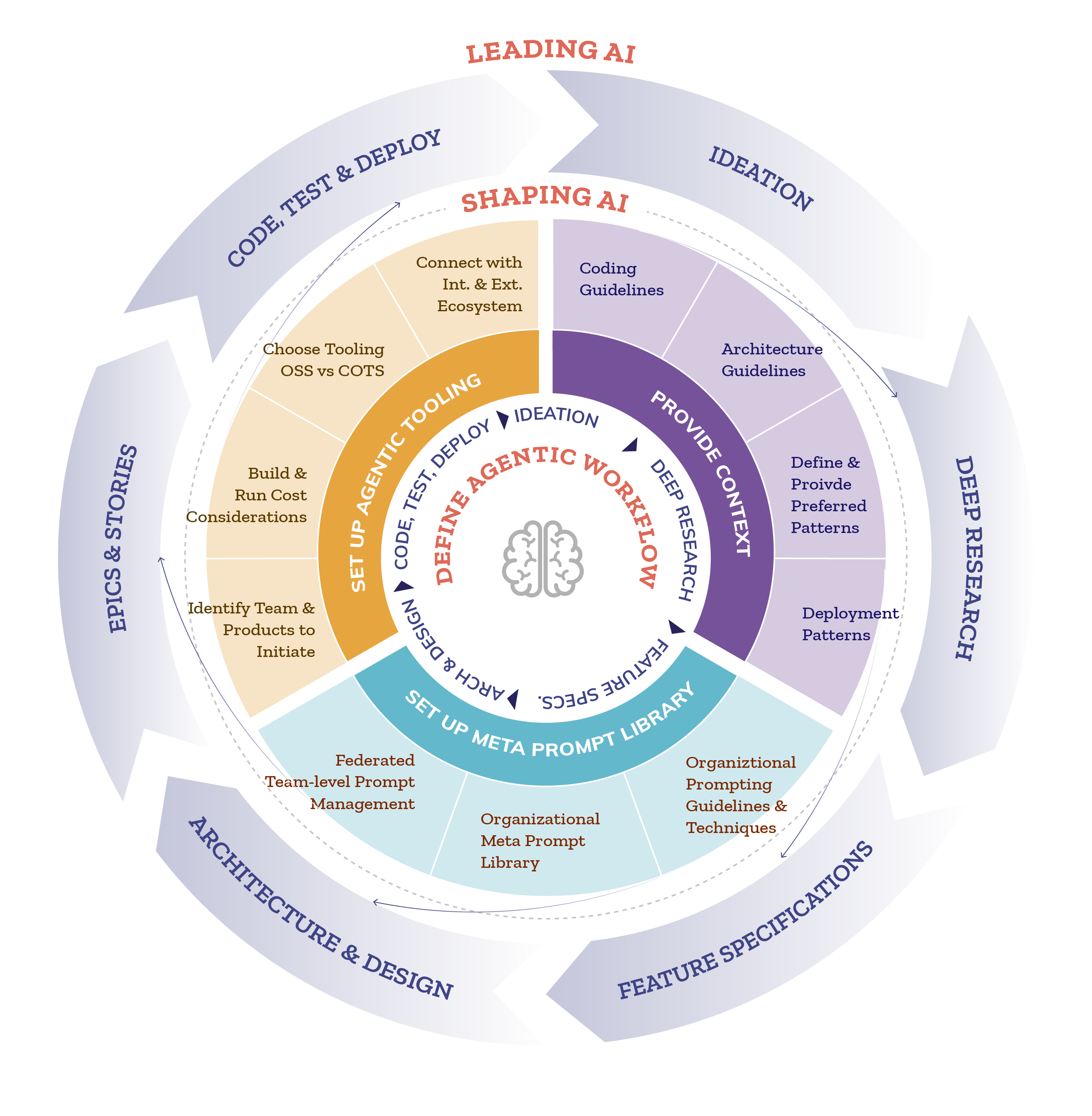
Leveraging Agentic AI required us to approach this across two key steps:
Step 1: Shaping AI
The first step was Shaping the AI and setting it up with the Agentic Workflow, Meta and project level Prompt Engineering, providing it the relevant technical and business context and setting up the Specification and Test driven development approach and the relevant tools ecosystem. These are described in detail below:
Key Components of Agentic AI Development
The project leveraged six critical components to drive engineering efficiencies:
The Agentic Workflow served as our project’s custom development roadmap. This workflow was specifically tailored to the complexity of the EMR system, covering the entire cycle from start to finish:
Explore (deep research to understand the healthcare domain)
Plan++ (breaking features down into manageable stories)
Implementation (writing the actual code while strictly following our project guidelines)
Testing (automatically generating and validating every piece of code).
The Prompt Engineering strategy was essentially how we communicated with and directed the AI. We established specific instructions at two levels:
Meta Prompt Library where organization-wide strategies were formally stored to ensure consistent behavior across projects
Project-Specific Prompts, which were custom instructions designed to guide the AI agents through detailed tasks like initial feature exploration, generating stories, and writing the actual code.
The Context Engineering strategy was absolutely essential for the AI’s effectiveness. The core idea was to ensure the agents had a comprehensive knowledge base by providing them with both technical guidelines and crucial business context.
Technical Context included all the “how-to” information for the code. This covered detailed rules for the backend (like API design, database schemas, and repository patterns), guidelines for the frontend (component building and data fetching), and specific instructions for how to use all the different tools in the ecosystem.
Business Context provided the “why” behind the code. This was equally critical, consisting of a general system overview, specific domain requirements (such as how to manage documents or extract data), and the necessary integration of clinical standards (FHIR R4, SNOMED CT). By giving the agents this full picture, we made sure they didn’t just write code, but wrote the right code for a highly regulated environment.
The core practice was Specifications-Driven Development, meaning every task was managed and executed using structured templates as the definitive plan. This process relied on three key documents:
Feature Templates, which were used to capture high-level feature descriptions along with a clear breakdown into smaller stories
Story Templates, which provided the detailed implementation specifications for development tasks, complete with clear acceptance criteria
Architecture Decision Documents (ADR), which were formally used to record and communicate the rationale behind every significant architectural choice made on the project. This ensured that the specifications, not ad-hoc ideas, were the single source of truth for all development work.
The Test-Driven Approach was a fundamental practice for the team, focusing relentlessly on ensuring both clinical accuracy and high code quality. This involved mandating the use of pytest with testcontainers for robust integration testing on the backend and Vitest along with Testing Library for the frontend. Crucially, this process was turbocharged by AI-assisted test generation from the specifications, which made the approach systematic, efficient, and ensured that maintaining high test coverage was a non-negotiable quality gate for all work.
The Tools Ecosystem was a critical element in the project’s success, integrating various specialized applications to drive development efficiency:
Claude Code served as the primary AI development assistant, handling the bulk of the code generation and implementation tasks.
Just was employed as a simple command runner, streamlining development tasks and processes for the team.
MCP (Model Context Protocol) was vital for context management and tool integration, ensuring the AI agents had the necessary information and access to different components.
GitHub Projects was used for centralized story and feature card management, providing a tracking system for progress.
Tach was integrated specifically to enforce dependency rules, thereby maintaining the integrity and modularity of the project’s complex architecture.
Step 2: Collaborating and Leading with AI
Creating and following a replicable implementation framework through the Explore, Plan, and Implement phases enabled the developers to collaborate very effectively with and lead the various agents through understanding the approach in the developers’ styles, apply the provided templates and code, test, and deploy the software.
Phase 1: Explore
Deep research and brainstorming to generate feature specifications.
Process:
Deep Research Agent: Conducts comprehensive research on healthcare standards, EMR systems, and domain requirements
Brainstorming Sessions: Q&A-based sessions to refine understanding and generate feature ideas
Feature Specification Generation: Creates detailed feature specs based on research findings
Example Exploration Outputs:
EMR standards research (FHIR R4, SNOMED CT)
Competitive analysis of existing EMR systems
Feature specifications for document management, patient conditions, summarization
Tools Used:
ChatGPT Deep Research for extensive domain research
Claude for interactive brainstorming sessions
Custom prompts: /generate-prompt:feature-exploration
Phase 2: Plan
Feature-to-story breakdown and project management workflows.
Process:
Feature Analysis: Decompose features into implementable stories
Story Creation: Generate detailed story specifications with:
Clear descriptions and acceptance criteria
Technical implementation details
Task breakdowns
Definition of done
Story Management: Upload to GitHub Projects for tracking
Story Review: Validate specifications before implementation
Example Planning Outputs:
Feature cards in GitHub Projects
Story specifications in markdown format
Implementation task lists
Priority and dependency mapping
Tools Used:
GitHub Project manager agent for card management
Custom prompts:
/generate-prompt:create-story-and-featuresStory validation:
/verify:story-spec-validation
Phase 3: Implement
Story implementation with code guideline adherence and feedback loops.
Process:
Story Implementation: AI-assisted coding following architectural patterns
Code Guideline Generation: Iterative improvement of code standards through feedback
Testing: Automated test generation and execution
Code Review: AI-powered code review before human review
Implementation Workflow:
Select story from backlog
Generate implementation prompt using /generate-prompt:implement-story
Implement with adherence to:
Architectural patterns (DDD, CQRS, Event-Driven)
Code guidelines (in
docs/code-guidelines/)Type safety requirements
Run just check (linting + unit tests)
Fix any issues
Commit with structured commit message
Create pull request with summary
Key Implementation Features:
Pause/Resume:
/implement:pause-storyand/implement:resume-storyfor context preservationCode Quality: Automated enforcement via ruff, pyright, ESLint
Testing: just check runs all tests before committing
The ‘intelligent Engineering’ Framework
In developing the application, the engineering team pioneered an ‘intelligent Engineering’ (iE) framework. It allowed us to properly set up the AI (by defining the workflow, providing context, creating specific instructions, and integrating tools) and then run the entire development process. This AI-driven process, or “Agentic workflow,” was comprehensive. It managed everything from the very first idea and research (Feature Exploration) all the way through to writing detailed plans (Story Creation), coding, testing, code reviews, and finally, deploying the software (Implementation and Deployment).
Key Lessons
Through the journey of this project, we were able to derive some key lessons across Structured Workflows, Context Management, Tool Integration, and driving Document-driven Development.
Structured Workflows
| Context Management
|
Tool Integration
|
|
Agreed Best Practices
Without a common set of rules, the quality of the code generated by the AI would have become messy very quickly. To prevent this, we established these essential practices that everyone must follow:
Always Start with Exploration
| Specifications Before Implementation
|
Iterative Code Guideline Development
| Test-Driven Mindset
|
Structured Commits and PRs
| Human Owns the output
|
Impact
The results of Project xEMR clearly demonstrate that Agentic AI workflows can fundamentally transform the entire software development lifecycle, from the initial research phase all the way through to deployment. The team achieved several critical impacts that significantly accelerated the project’s delivery:
Agentic AI workflows transformed the entire software development lifecycle
90% of the specifications, stories, code, tests, implementation done by AI but verified by developers.
300% increased productivity per engineer on the team.
In addition, the team was able to drive better architecture through consistent patterns, higher quality documentation that evolves with the codebase and improved developer experience through context-aware assistance.
Conclusion
Ultimately, this case study points to a clear future, one where AI agents take over the routine tasks and all the boilerplate code, freeing human developers to focus their expertise on the most challenging and valuable work—system architecture, business logic, and innovation. The main takeaway isn’t if AI will transform software development, but how quickly teams can adapt to leverage its power.
We learned a few key lessons for this transition:
Agentic AI acts as an AI as a Force Multiplier, meaning it doesn’t replace developers but dramatically amplifies their capabilities.
Its effectiveness relies on the principle that Context is King—providing comprehensive technical and business context is critical for intelligent assistance.
Moreover, establishing Structure Enables Scale through clear meta prompts, templates, and workflows makes the AI’s help repeatable.
Continuous improvement through Feedback Loops Matters, requiring the constant refinement of guidelines and instructions.
Finally, a robust Tools Ecosystem, seamlessly integrated with existing tools like Git, GitHub, and IDEs, is essential for a smooth workflow.

