
Introduction
Deciding between Extract, Transform, Load (ETL) and Extract, Load, Transform (ELT) is one of the most important decisions a data engineer has to make. Transforming data before loading (ETL) or after loading (ELT):
can shape how efficiently we handle data
how flexible we are in adapting to changing requirements
and how well we scale
As a data engineer, I’ve had many opportunities to work with various data pipelines and tools. A commonly asked question is ‘Should we use ETL or ELT?’. Both methods have their place in data engineering, but they serve different purposes and are suited for various scenarios.
In this post, based on my experience, I will explore the key differences between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform). I hope this helps readers understand which approach might be better suited for specific use cases. From flexibility and scalability to speed and compliance, both methods have their pros and cons, and the right choice can make a huge difference in how effectively you manage your data.
ETL in Action
In this section, I will walk you through a real-world example of an ETL pipeline. This was part of a project that processed billions of bids daily against a collection of inventory. To help businesses improve bidding information for the inventory, we started generating insight reports daily for these bids. This process involved extracting data, aggregating it as part of transformations, and loading it into a relational database for analysis. Below is a diagram that provides an overview of the pipeline.
Let’s break down the core concepts and tools used in this pipeline:
ETL Process Breakdown
Extraction (E):
With the help of the Mongo Federation service, a scheduled job runs every hour, converting billions of bid data to a columnar file format. This data is read from the MongoDB secondary node.
The data is exported incrementally from selected collections and outputs that data as Parquet files to cloud storage, i.e., Amazon S3 buckets.
To ensure efficient organisation and accessibility, we followed a structured folder hierarchy in S3, organising data by year/month/day to facilitate the creation of appropriate schemas and partitions during the transformation phase. Organising data in this fashion is also one of the recommended best practices.
Transformation (T):
AWS Glue detects the schema of the data and updates the AWS Glue Data Catalog whenever new files come in, making it queryable in AWS Athena.
Using AWS Athena, we perform an aggregation query on the extracted raw data, grouping it by inventory per hour.
The transformation produces aggregated output that is stored temporarily in Amazon S3.
Load (L):
Once the data is transformed, the final step involves loading the aggregated data from Amazon S3 into PostgreSQL.
The S3 output is archived after loading.
This pipeline showcases the classic ETL process, where the data is transformed before being loaded into PostgreSQL. By handling transformations upfront with AWS Athena, the data becomes immediately usable once it is loaded into the relational database.
ELT in Action
This project had multiple OLTP systems which made it difficult to analyse and generate insights that will help the business to make data-driven decisions. An ELT pipeline was built that extracts daily snapshots from multiple MS SQL databases and loaded into a data warehouse to create an aggregated view for the business across different OLTPs. In this pipeline, the raw data is first loaded into Google BigQuery, where transformations are later performed using dbt (data build tool).
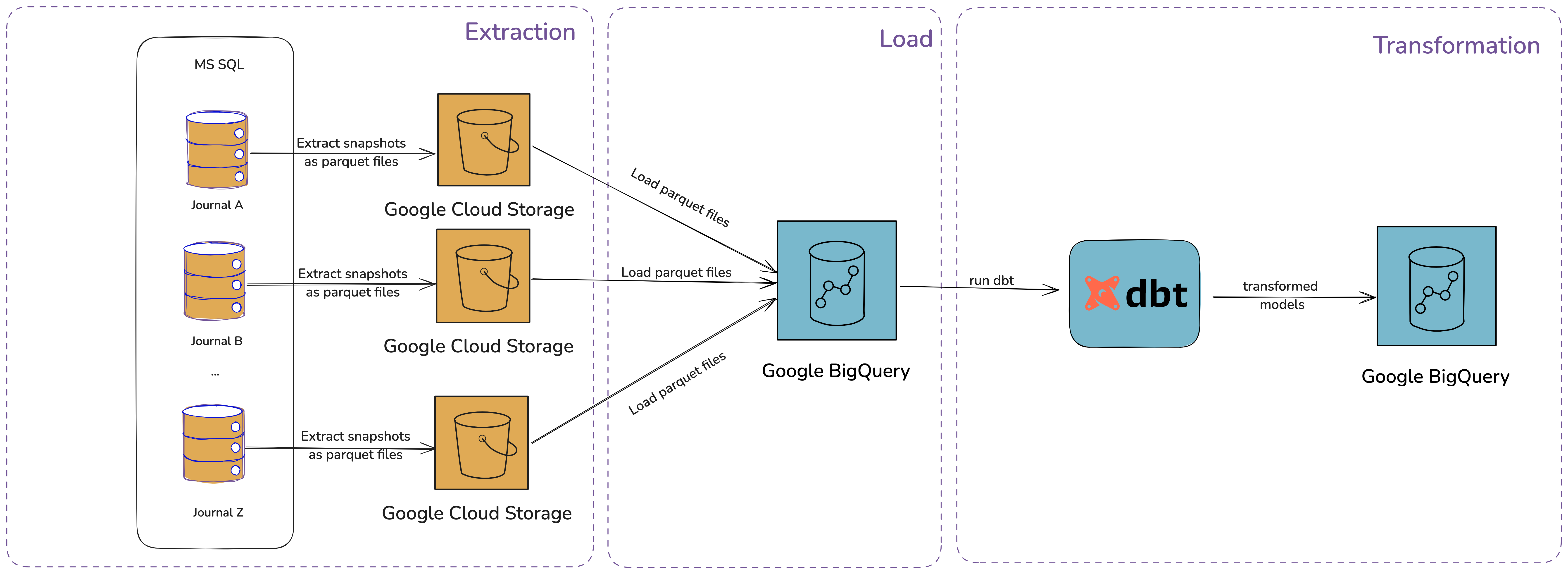
ELT Process Breakdown
Extraction (E):
A job runs daily, which performs a batch ingestion of snapshots of raw data from multiple MS SQL databases.
Apache Beam and Google Dataflow orchestrate the extraction and processing, saving the output as Parquet files in Google Cloud Storage.
Load (L):
The Parquet files are then loaded into Google BigQuery, where the raw data is made available for transformations and further analysis.
Transformation (T):
The transformation begins with schema validation and data tests to ensure the integrity and quality of the raw data.
After testing, complex SQL queries were run in BigQuery to transform the raw data into valuable data products, which were then used by BI tools for reporting and analytics.
This ELT pipeline allows for the flexibility of loading raw data into BigQuery first, where transformations could be applied as needed.
ETL vs ELT
Let’s compare the ETL and ELT processes based on key parameters and see how these factors played out in the above-mentioned projects.
Schema
ETL is “schema-on-write,” i.e., data is transformed before being written into the target system. This ensures the data is ready for immediate use but adds time to the loading process. In the ETL project, we saw that the selected data is extracted and transformed before being stored in the Postgres DB, and hence, the analysts can start referring to the transformed data to get insights.
ELT is “schema-on-read” i.e., data is transformed after being loaded into the target system. This allows for flexibility in loading data and making it available in future but requires transformation when data is read for analysis. In the above ELT project, we saw that the raw data is first loaded into Google Big Query and then later based on use cases the transformations would be applied to the selected data before making it available for analysis. Hence, the analysts cannot start referring to the data until it is transformed to get insights.
Data Availability
ETL: Based on the use cases related to analysis, the selective data that needs to be extracted and transformed needs to be identified. Hence, in case of new use cases where the data is not available, analysts have to wait until the required data is ETL’d. In the ETL project, instead of exporting all the MongoDB collections only the bids-related collections are exported as we need to derive insights only for bids.
ELT: In the ELT model, we store all the structured and unstructured data irrespective of what use cases need to be considered for analysis. These use cases are identified and accordingly a transformation step is added, which loads the data for further analysis. In the ELT project, in case the analysts want to refer to the raw data it will be available at any time assuming appropriate permissions are in place.
Data Accessibility
ETL: Regarding access to the raw data, the sources from where it is extracted control the access (in this case, it is MongoDB). Also, in case we are storing the intermediate extracted data before transforming then it is subjective how the access to that data is governed (in this case it is AWS S3). In the ETL project, the source systems are MS SQL databases, which could be internal or external, hence the analysts would need to seek permission to access them. Also, the intermediate parquet files are stored in the S3 bucket, which is again controlled with restricted permissions in the AWS. Hence, data availability is difficult in this case as it is subjective to the permissions granted to data analysts.
ELT: In terms of data availability, it is already loaded into the data warehouse and it is available if the users have access to it. In the ELT project, we load all the data in Google Big Query. The permission to the data models is controlled with dbt model access and table access. But in general, if the analyst wants to take a look at the raw data for analysis then they can access it easily as compared to the ETL project.
Flexibility
ETL: In terms of flexibility in extracting additional data and transforming the data in different ways, it is difficult as we would need to make changes to the entire linear ETL process. Also, we might not have all the historical data related to the additional data, which would have been archived in the OLTP systems. In the ETL project if we want to extract additional collections then we need to make changes from extraction, transformation, and load as well as rerun the pipeline in order to backfill the data. The insights that are already being generated in the past cannot be backfilled if the sources have already archived the additional data.
ELT: For transformation, we have the flexibility to transform the same data in different ways at the same time as well as additional data that was skipped from transformation since the entire raw data is already present (assuming we extract all the raw data and load it in the cloud storage e.g., data lake). In the ELT project, we moved all the raw data from the sources to the data warehouse, giving us the flexibility to transform the additional raw data and also making the historical data available for backfilling. From a cost metric perspective though, retaining the raw data in the cloud storage with appropriate archival policy will be a better approach over the data warehouse.
Scalability
ETL: In an ETL project, the scalability factor is for the storage during load and for the compute engine during transformation. If the ETL is set up on-premise, it is not easy to scale up fast compared to on-cloud as ETL is resource-intensive. For example, if you are using any compute engine like EMR (Apache Spark), AWS Athena or Apache Beam with a cloud-hosted runner it will be faster to scale than on-premise. But in the case of a self-managed compute engine for example Apache Spark then the scalability needs to be evaluated to avoid any significant performance degradation in the transformation phase. In the above ETL project, as we are using the Mongo Atlas managed service and AWS Athena along with AWS S3, the scalability part is taken care of by the cloud solution.
ELT: If we use a cloud-based ELT model, it is much more easily adaptable to scale without any performance degradation. The cloud model of the pay-per-use model makes it a feasible option to focus on the problem by delegating the scalability of load and storage to the cloud provider’s native tool like Google BigQuery or AWS Redshift. In the above ELT project, we are using Google Cloud Storage and Google BigQuery as a data warehouse, which is easily scalable.
Maintenance
ETL: In the traditional ETL pipeline, the processing server added for transformation can increase the burden of maintenance in terms of infrastructure if it is self-hosted or on-premise as compared to cloud-based solutions. In the ETL project, we are using the AWS Athena, hence, the maintenance overhead is with the cloud service provider. If we were using any self-hosted Apache Spark cluster over EMR then the maintenance would be higher.
ELT: As the ELT process goes hand in hand with modern data stack as well and the storage and computing are cheap as compared to on-premise, the maintenance is not that much of a challenge in terms of infrastructure.
Storage
ETL: With ETL the storage required is quite less in contrast to ELT as we are storing only a subset of data post-extraction as well as transformation. In the ETL project, we are exporting only selected collections and storing the parquet files in S3 with an appropriate archival strategy. This avoids extracting data from the source again in case of rebuilds or backfilling. Also, we are storing only the transformed data in Postgres DB.
ELT: For ELT the storage required is quite high in contrast to ETL as we are storing the raw data (can be all if based on implementation pattern) and the transformed data. In the ELT project, we are storing all the data extracted from the sources in the data warehouse. Datawarehouse has its own strategy of saving the hot and cold data, which reduces the storage cost eventually.
Compliance
ETL: In terms of ETL, it is much easier to apply rigorous compliance standards to the selectively extracted data while performing transformation versus the entire raw data.
ELT: In terms of ELT, we move all the raw data to the data warehouse. If not careful then that can lead to problems in remaining compliant with regulations such as HIPAA and GDPR, particularly within the context of storing data on cloud services whose servers are located across borders.
Conclusion
So, you might still be asking yourself, “Which is better: ETL or ELT?” The reality is, there’s no one-size-fits-all answer. It’s not about one approach being better than the other but it’s about what fits your business needs. Each has its strengths.
ETL is best for legacy systems, compliance, and structured data needs, transforming data before storage for efficient future use.
ELT, favoured for modern analytics, excels with large data volumes, real-time access, and scalability, loading raw data first and transforming it as needed.
The right choice depends on your business needs—ETL for structured, compliant data workflows, and ELT for flexible, high-volume, and real-time data handling. Both methods can complement each other, depending on the complexity of your analytics.
In conclusion, there is no definitive “better” option—only what’s best for your specific use case.

