
With LLM embedding-based applications, it’s quite easy to understand and apply semantic meaning in machine learning algorithms. For example, you can use text embedding to feed to a classifier for rating user sentiment on user feedback or use it for RAG-based semantic search, etc.
What is Embedding
We understand words by mapping them in different dimensions. For example, relative terms such as good, better and best or low carb vs high carb food. If we represent the word by rating these values in different dimensions, it can represent the meaning in a certain sense. Embedding models provide this mapping for text to binary representation of “mathematical representation of the text” or a value that can be compared.

For example, in the context of healthy foods, certain foods might be attributed as good although they may not be good in the realm of tasty food. So, the rating for good is influenced by the majority of the population rating it. Basically, your representation may not capture the dimension I am interested in or it may rate differently than my expectations.
However, large language models are limited (or powered) by data that was used to train the model. Let’s check ground reality with Open AI embedding API.
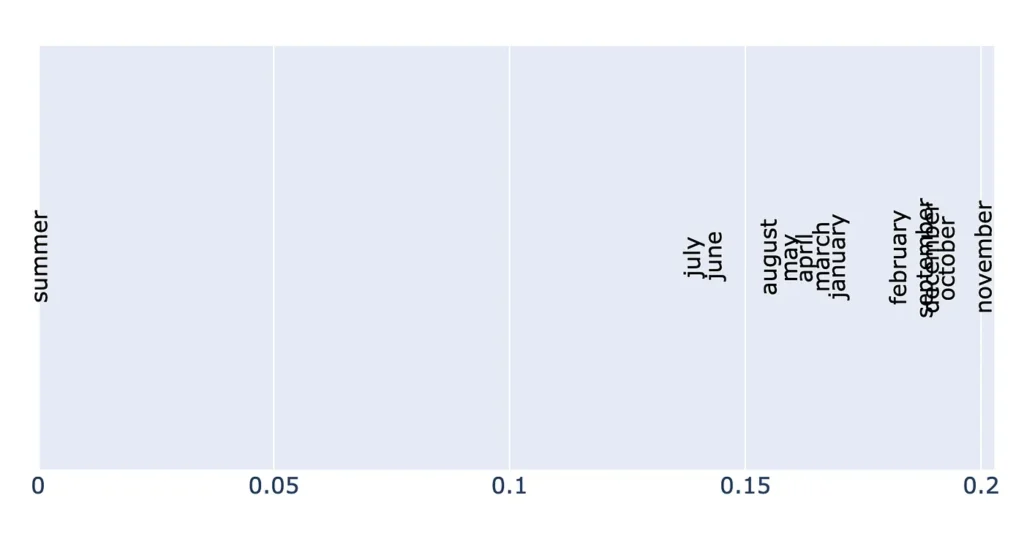
Here, we are checking which one of the 12 months is closer to summer in embedding space. You can clearly see from the results that the model assumes certain parts of the world as the globe.
Imagine using such an embedding for recommending products on an e-commerce website. You might see winter shoes recommended in summer! Of course, we can avoid it by explicitly handling the scenario. However, not all biases are known.
Biases
Bias is a statistical skew towards certain concepts over others. This can happen mainly due to two reasons:
- context — system prompts, prompt history while generating embedding.
- model weights — training data used in the embedding model having a bias in terms of number of samples representing various groups.
Here is a list of relevant biases that may impact business applications. (If you come across missing biases, please add them in the comments below.)
Geographical and cultural biases
- Seasonal associations (summer, winter): As the earlier example demonstrated, a model’s seasonal associations depend on its training data. Northern hemisphere bias could lead to nonsensical results.
- Cultural references and idioms: LLMs often include American/Western biases and miss local relevance.
- Location-specific knowledge: Models lack a grounded understanding of places.
Domain limitations
- Scientific, medical, legal fields: Models trained on general text lack specialized knowledge.
- Industry or business specifics: Each industry has its own lexicon, concepts and needs.
- Lack of real-world grounding: Models have no real experience to draw on.
Demographic biases
- Gender, race, ethnicity: Models perpetuate documented biases along identity lines.
- Age, generational differences: Training data skews young and lacks senior perspectives.
- Socioeconomic divides: Life experience varies tremendously with factors like wealth.
Mitigating embedding biases
While pre-trained models have limitations, we are experimenting and developing techniques to evaluate and reduce biases, including:
- Testing models using benchmark tasks to measure biases. However, this is limited to known biases. Models can have biases that are not caught by curated test data or scenarios. These are like unknown bugs in traditional software.
- Fine-tuning with domain / use case-specific data can reduce biases in the embedding. Filter training data to minimize representational imbalances and augment data to include diverse perspectives.
Carefully evaluating and fine-tuning embeddings is crucial to overcome limitations and biases for sensitive applications. With proper diligence, these powerful models can be safely leveraged to provide a broad understanding of language.
Have you had any similar experiences? Share in the comments below.

