
Terraform is a great tool to automate your infrastructure provisioning. One of the aims of the automation is having an ability to reproduce the deployments and reducing the time required to do the releases.
Another important practice is to de-risk the deployment, allowing the teams to deploy continuously even during the working hours.
This necessitates that the production systems should be continuously available and no downtime window is allowed (like in the old days).
One of the ways you keep the services available throughout the deployment is to have a rolling deployment strategy.
Rolling deployment can be defined as a deployment when newer instances or resources (like containers) are first added to the infrastructure. The deployment process waits for newer instances to be fulled operational and in service and then only older resources are properly drained and removed.
Rolling deployment vs Blue-green deployment
The point to keep in mind is that rolling deployment is not the same as blue-green deployment.
In case of successful rolling deployment, you will just have a single service version running in an environment at the end of the deployment. The decommissioning of the older version is performed as part of the deployment itself.
In the case of blue-green deployment, the old and new versions of the service are kept running in parallel for some time. Once everything works in the new version in terms of functionality older version is gradually decommissioned. So decommissioning of the older version is generally a separate step in blue-green deployment. Blue-green deployment generally gives you an opportunity to test the new version before making it live. Also, the old version might be kept running for some time even when a new version is live and serving the traffic.
Let’s see how a rolling deployment might look like on AWS infrastructure.
Rolling deployments on AWS
In the context of rolling deployment, we are going to talk about the deployment of a single service. Your overall system might consist of multiple such services, you can extend the same practices to perform rolling deployments for other services in your system.
Overview of service infrastructure
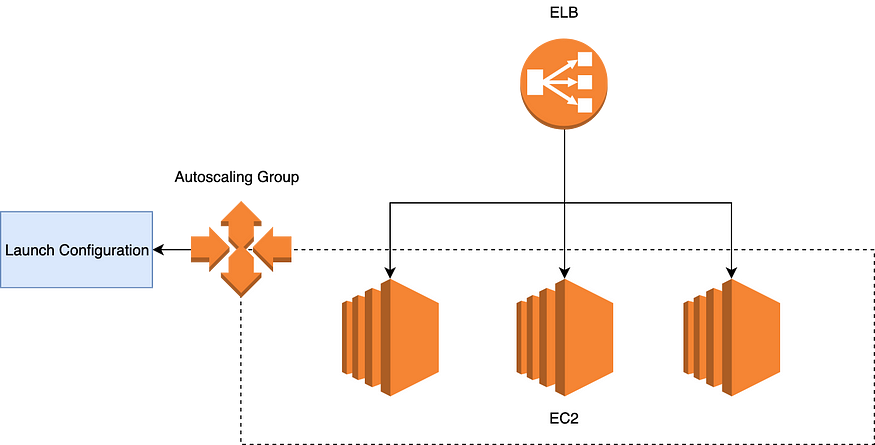
Here we are using an ELB (Classic Load balancer), an autoscaling group, a launch configuration, and EC2 instances.
The load balancer is sending requests to instances in round-robin fashion. In the case of scaling out event auto-scaling group will start EC2 instances as per the launch configuration provided.
Most of the time, the deployment is required because a new AMI is generated with a newer version of the application.
In this case, we want our rolling deployment to look like this:
- A new launch configuration will be created.
- A new auto-scaling group will be created which is associated with the new launch configuration.
- The auto-scaling groups will still be associated with the same load balancer (ELB).
- New Auto-scaling will create new instances under the same load balancer. The new instance will use the new launch configuration hence will use the new AMI. These instances are where version 2 of the application is running.
- Once the new instances are in service, old launch configuration, and autoscaling groups will be deleted. Before the deletion of the instances under the autoscaling group, connections from the load balancers will be drained. This allows ongoing requests on older instances to complete.
Let see how can we do the above with Terraform configuration.
Terraform for rolling updates
The full code is available here: https://github.com/prashantkalkar/terraform_rolling_deployments (Refer to README to run the application).
We will be using the Nginx service as our application. The service will be running on port 80 on the instances.
Let’s look at the terraform code to create the Autoscaling group and the launch configuration.
resource "aws_launch_configuration" "rolling_deployment_launch_config" {
name_prefix = "rolling_deployment_lc_"
// AMI with nginx installed. Refer nginx.json packer configuration for creating it.
image_id = "ami-034836f1b27723260"
instance_type = "t3.nano"
security_groups = [aws_security_group.rolling_deployment_instance_sg.id]
root_block_device {
volume_type = "gp2"
volume_size = "8"
}
lifecycle {
create_before_destroy = true
}
}
resource "aws_autoscaling_group" "rolling_deployment_asg" {
name = "rolling_deployment_asg_${aws_launch_configuration.rolling_deployment_launch_config.name}"
launch_configuration = aws_launch_configuration.rolling_deployment_launch_config.name
load_balancers = [aws_elb.rolling_deployment_elb.name]
availability_zones = data.aws_availability_zones.zones.names
min_size = 3
max_size = 3
// ELB health check should mark the instance as healthy before this time.
health_check_grace_period = 300
health_check_type = "ELB"
wait_for_capacity_timeout = "10m"
wait_for_elb_capacity = 3 // generally set to ASG desired capacity
lifecycle {
create_before_destroy = true
}
}Create before destroy
Here we have defined a lifecycle for launch configuration (LC) and ASG as create_before_destroy = true. As the name suggests this creates the new LC and ASGs before destroying the old one. This ensures that the application keeps serving the requests during the deployment. The new ASG instances will start excepting the requests before we start destroying the old ASG instances.
Notice another thing is we have used generated names for ASG or LC. For LC, we have just provided a name_prefix. Terraform will generate the actual resource name with name_prefix and a randomly generated value.
Similarly, the name of the ASG depends on the name of the Launch configuration (LC). Since the LC name is generated, the ASG name will also have the generated component.
Dynamic names are required since we are creating new resources first while the old already exists (create_before_destoy). If you try to use named resources their names will clash with old existing resources. Also making ASG name dependent on LC name ensures that if LC is changed ASG is also recreated ensuring instance creation with new Launch configuration.
ASG Healthcheck configuration
The next thing to notice is ASG has an ELB based health check as follows.
// ELB health check should mark the instance as healthy before this time.
health_check_grace_period = 300
health_check_type = "ELB"The ASG instances once created are by default considered healthy unless marked as unhealthy by the health check mechanism. The health check grace period is the period in which (un)health reporting will be ignored and instances will be assumed to be healthy. The grace period allows the instances to get initialized, the application to start properly and start responding to the health endpoints calls from ELB.
Ensure, the health check grace period is set to sufficient value to allow application startup.
ASG and Load Balancer
Also note, that ASG associate itself with the load balancer (ELB).
load_balancers = [aws_elb.rolling_deployment_elb.name]The key thing to understand here is, both old and new ASG instances will be under the load balancer (ELB) at the same time for a short period of time while old instances are getting drained and newer instances have started serving the requests.
Waiting for the load balancer capacity
We need to ensure that terraform waits for the new instances to be in service under the ELB before moving on to destroy the old instances.
Following configuration at ASG ensure just that:
wait_for_capacity_timeout = "10m"
wait_for_elb_capacity = 3 // generally set to ASG desired capacityHere we are saying that Terraform should wait up to 10 mins for the instances to be in service.
ELB capacity ensures that at least those many instances are services the incoming traffic under the ELB. This can be set to the desired capacity of the ASG.
Load balancer health check
Lets now look at ELB configuration for the application health check.
resource "aws_elb" "rolling_deployment_elb" {
name = "rolling-deployment-elb"
availability_zones = data.aws_availability_zones.zones.names
security_groups = [aws_security_group.rolling_deployment_elb_sg.id]
listener {
lb_port = 80
lb_protocol = "http"
instance_port = 80
instance_protocol = "http"
}
health_check {
healthy_threshold = 5
unhealthy_threshold = 2
timeout = 5
target = "HTTP:80/"
interval = 30
}
connection_draining = true
connection_draining_timeout = 300
}Here we have defined the ELB with the listener for incoming traffic on port 80 which in-turn forwarded to port 80 where our Nginx is running.
The interesting part from the rolling deployment point of view is the health check configuration. The ELB will send an HTTP request to every instance on port 80 with path /. If the response from the service endpoint is 200 then the service/application will be considered healthy.
The health check is done every 30 seconds and the instance is considered healthy for 5 consecutive success responses. So the total process to mark the instance healthy will take at around 150 seconds once the application has started.
Make sure, that health_check_grace_period at ASG configuration is high enough for the instances to mark as healthy.
ELB and connection draining
Once the new instances are up and running and serving the traffic. The old instances have to be removed.
Before removing the instances though, we need to ensure that we provide enough time for the instance to complete requests under service.
This is achieved by draining configuration at the ELB.
connection_draining = true
connection_draining_timeout = 300Once the ASG is marked for deletion by Terraform during the deployment, ELB will stop sending new requests to old instances (Note, this will happen once the newer instances are InService). This means that the instances are now in a draining state.
ELB then wait draining_timeout period to allow the application to complete the ongoing requests.
Once the draining_timeout is over, the instances will be terminated from the ASG and eventually old ASG will be removed as well. This will complete the rolling deployment with a new version of the application running on new instances and old instances terminated.
Failures during deployment
In case of any failures during the start of the new version of the application, the Terraform process will be terminated with failure. These mean old instances will continue to serve the traffic.
If the failure occurs, while termination and clean up of old instances then new instances are still servicing the traffic.
Terraform will mark the ASG as tainted in case of the failure and will try to perform the rolling update during the next run.
DB Migration Challenges
Zero downtime rolling deployments are easy when the new application deployment does not require corresponding changes to DB schemas.
In the case of DB changes, special considerations are required for zero-downtime deployments. The general idea is to manage the compatibility between DB schema and application versions.
Details discussion of these techniques is not possible as part of this blog post.
Possible drawbacks of this approach
The above approach does the rolling deployments while ensuring the application is running throughout the deployment.
One possible downside of the approach is the re-creation of the ASG for every deployment. If you are capturing the metrics at the ASG level and want to track long terms trends then re-creation of ASG will be a problem.
This may and may not be a problem in practice, since due to the dynamic nature of the cloud infrastructure and move towards immutable infrastructure you may still prefer to perform deployments by replacing old infrastructure rather than changing in place.
Alternative Approaches
I have used the following 2 approaches in the past which can be used for rolling deployment.
- Combining Terraform and CloudFormation together. CloudFormation provides the rolling deployment capacities for the ASG out of the box. So ASG can be managed with CloudFormation stack. This stack can be created and managed by Terraform.
- Using a custom script (python or shell) to perform the rolling deployment. Terraform can be configured to execute the script every time a new launch configuration is created. This can be done with the help of the provisioner on the Terraform null_resource.
The alternative approaches can be converted as part of the separate blog posts.
I hope this will help you set up your rolling deployment in the cloud.

