

While searching for any information on the Internet, it’s important to determine whether the results being fetched are relevant to what is being searched for. Most of us use search engines like Google, Bing, Yahoo!, or DuckDuckGo to find answers, but do these search engines always return the same results? Interestingly enough, that is not the case. Let’s uncover the mystery behind why the same search term can yield different results across different platforms.
For example, if the user is searching for something specific, they might just Google it. This type of search, where the user enters a keyword and expects results based on that keyword, is called a keyword-based search. In addition to traditional keyword searches, advancements like Large Language Models (LLMs) have introduced new ways to retrieve information, such as Retrieval-Augmented Generation (RAG). RAG allows for more advanced searches by combining the power of LLMs with external information. While the user can still perform a keyword search in a RAG system, the challenge lies in ensuring that the system understands and retrieves the most relevant answers based on those keywords. LLMs have also enabled semantic/contextual searches in addition to keyword-based searches.
How Does RAG Work
Let’s say the user searches for the term “DBT” in an existing RAG application. The system will retrieve the context from the vector database, as shown below:
Data pipelines have been in production for over a year now;
earlier,there were 1-2 production incidents per month on an average,
all of which were reported by automated alerts and monitoring solutions in place.
Time to resolution was about 8 hours on an average to detect and release a fix into production.
For the tech stack, we chose dbt for efficient, best-practice data transformation and model management.
Apache Airflow was used to automate workflows for efficient data processing and scheduling,
and providing a powerful, reliable solution for managing pipelines.
re_data enabled upfront observability, helping us catch and rectify bad data in pipelines,
ensuring a reliable end productWorking of a Basic RAG Application
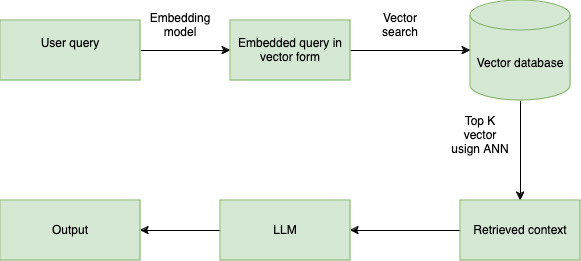
Let’s analyse what is happening behind the scenes. As soon as the user enters the query, the embedding model will convert the human-understandable query into a machine-understandable vector representation of a configured dimension. It will retrieve the appropriate top K vector using the ANN (Approximate Nearest Neighbour) algorithm and the retrieved context will be passed to LLM and it will generate the answer.
Here, we can notice that the entire output is dependent on the context of what LLM has received. But the curious part is that the retrieval of the context from the vector database depends on the user query.
What if the system or application transforms the user query into a better query that paraphrases the user query to make it more suitable for a RAG application?
Consider a scenario where the user is interested in leveraging data engineering for their business and they submit the following queries:
Question 1: Lineage graphs in DBT
Question 2: How does DBT lineage tracking improve data quality?
Between these two questions, it’s clear that the second query is more specific about what the user is exactly expecting. Whereas in the first question, we can notice that the query is a more generic one and a keyword-based kind of result. As explained above, the RAG application will return results that may be inaccurate or more generic.
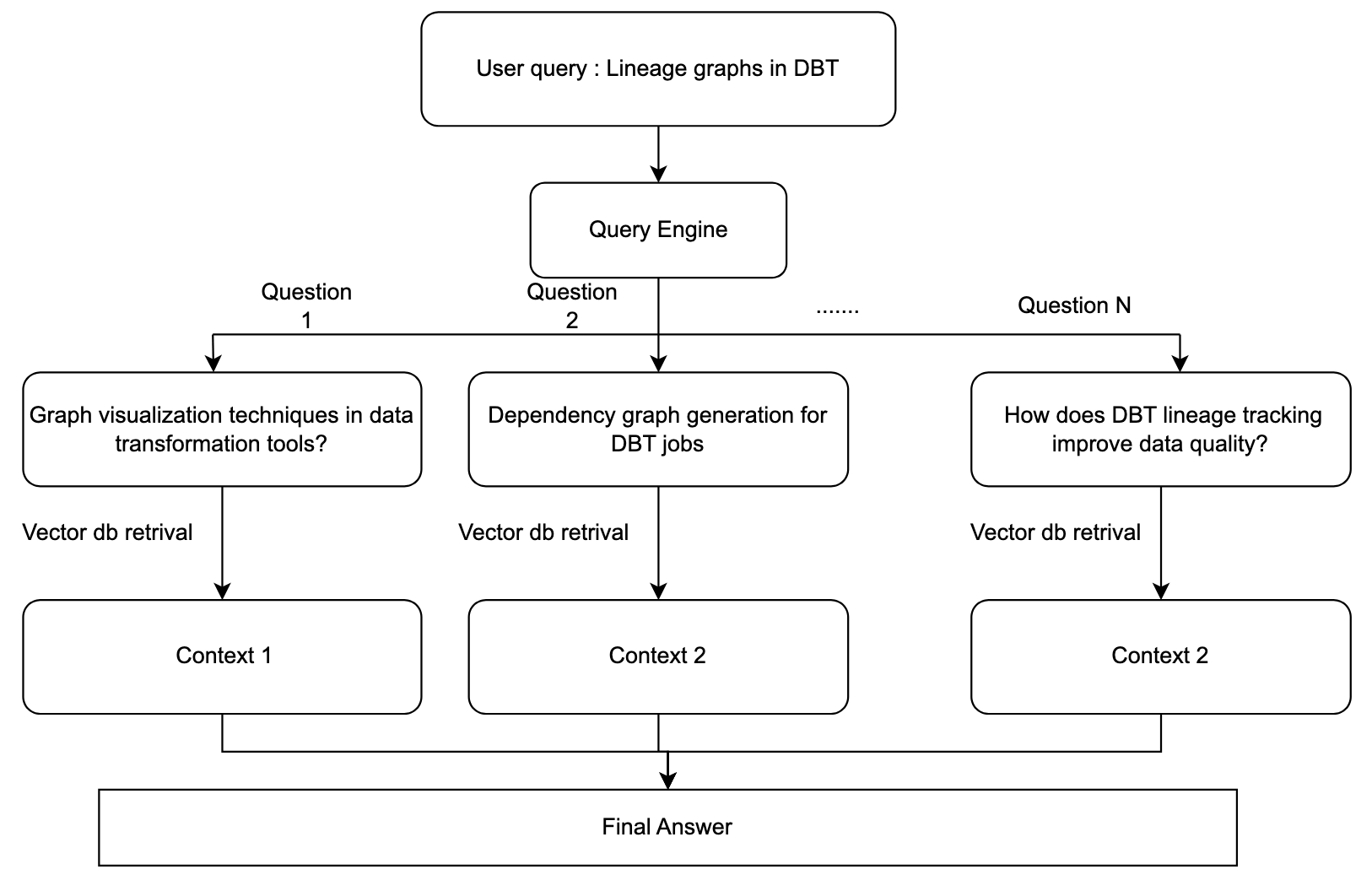
High-level Architecture
Given below is the high-level architecture to perform query decomposition.
Steps to Create a RAG Application
Follow the steps below to set up an Embedding model, Vector Database, and Ollama. We are using the following tools:
Milvus for a vector database
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
from langchain_milvus import Milvus
from langchain_ollama.llms import OllamaLLM
from langchain_ollama.llms import OllamaLLM
MODEL_NAME = "BAAI/bge-small-en"
MODEL_KWARGS = {"device": "cpu"}
ENCODE_KWARGS = {"normalize_embeddings": True}
MIVLUS_URI = "http://localhost:19530"
embedding_model = HuggingFaceBgeEmbeddings(
model_name=MODEL_NAME, model_kwargs=MODEL_KWARGS, encode_kwargs=ENCODE_KWARGS
)
def get_vector_store_retriver():
return Milvus(
embedding_function=embedding_model,
connection_args={"uri": MILVUS_URL},
).as_retriever()
def get_llm():
return OllamaLLM(model="llama3.1:8b")Step 1: Load the data from the DBT documentation
In this step, we will load the data using the lang-chain web-based loader from the link.
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.documents import Document
resource_url = "https://www.getdbt.com/blog/guide-to-data-lineage"
loader = WebBaseLoader(resource_url)
docs = loader.load()Step 2: Split the given question into ‘N’ different sub-questions
In this process, we will be splitting the given question “Lineage graphs in DBT” into meaningful subquestions so that the system can retrieve the desired chunks from the vector database.
To achieve this, we need to instruct the LLM on what to do using the prompts.
from langchain_core.prompts import ChatPromptTemplate
query_decompostion_prompt_template = f"""You are an AI language model assistant. Your task is to generate five
different versions of the given user question to retrieve relevant documents from a vector
database. By generating multiple perspectives on the user question, your goal is to help
the user overcome some of the limitations of the distance-based similarity search.
Provide these alternative questions separated by newlines
the out put should looks like a question framed by the prompt engineering expert in that domain.
Original question: {question}
"""
prompt_perspectives = ChatPromptTemplate.from_template(query_decompostion_prompt_template)Step 3: Define the chain to perform the query decomposition
In this step, we will be defining the sequence of operations to be performed to get ‘N’ subquestions for the given query.
query_engine = (
prompt_perspectives
| get_llm()
| StrOutputParser()
| (lambda x: x.split("\n"))
)
retriver = get_vector_store_retriver()
retrieval_chain = generate_queries | (lambda x: print(x)) | retriver
docs = retrieval_chain.invoke({"question": question})Execution of the above code leads to the following output:
Question 1: What is DBT's visualization for data dependencies?
Question 2: How does DBT represent data transformations
Question 3: Optimizing DBT workflows through graph-based dependency analysis
Question 4: Identifying impacted tables after a change in DBT
Question 5: Dependency graph generation for DBT jobs
Here, we can see that the subqueries focus on how the Lineage graph can be used in the data engineering pipeline for better visualisation of dependency analysis.
Step 4: Use the existing RAG method
In this step, we will get the answer for each question using the existing RAG method present in the application.
Step 5: Combine all the contexts to generate the final answer for the given user query
combined_prompt_template = """
You have been given several answers to decomposed sub-questions, which were generated as part of answering the main question. Your task is to combine these answers into a single, concise, and comprehensive response to the source question.
Sub-questions and their answers:
{decomposed_sources}
Now, based on the above information, provide a single, crisp answer in less than 500 words to the following source question:
user query: {user_query}
"""
prompt = ChatPromptTemplate.from_template(template)
rag_chain = (prompt | get_llm() | StrOutputParser())
result = rag_chain.invoke({"decomposed_sources":decomposed_sources,"user_query":query})Advantages of Query Decomposition
The precision of the response: Breaking down a complex user query into well-structured sub-queries, leads to more efficient retrieval of the vector embedding from the vector database. Because each sub-query will be targeted to retrieve a different set of information from the given knowledge base. We can observe a context precision of more than ~90 %.
Ambiguity: This process will reduce the ambiguity in the query by thinking from different points of view. Further, we can leverage the existing domain knowledge of LLM to understand the requirements precisely.
User experience: We can observe a drastic change in user satisfaction by removing the burden of elaborating the query on the user.
Conjunction parsing: Suppose the user query is a combination of two or more questions. Then, by using the query decomposition technique, we can break down the given question into sub-questions, and process them.
Disadvantages of Query Decomposition
Time of execution: The entire time of execution increases due to the overhead of combining the answers to each sub-question. (assuming the retrieval from the vector database is performed parallelly)
Hallucination: There might be a possibility that the LLM will hallucinate while combining the answers to all the sub-questions.

