

Introduction
When I first started building my own model (a language model for my need ), I went through a lot of videos and built it from scratch. While doing so I noticed something interesting: Speed feels like intelligence. A model that answers in 300ms feels brilliant, while the same model taking 3 seconds feels broken, even if the answers are identical. Of course, not all extra time is wasted. With reasoning models, those additional seconds often reflect deeper “thinking” running through more steps, generating intermediate tokens, or verifying an answer. Users will accept that trade-off if it feels intentional. What breaks the experience is when latency shows up as unexplained lag rather than as purposeful reasoning.
That’s why latency isn’t just a technical metric; it’s a user-experience dealbreaker. In this article, we’ll explore how to put large language models on a Latency Diet: trimming away the “millisecond fat” that silently bloats response times, while preserving the reasoning power that makes them smart.

What P95 Really Means
When I first started optimizing AI systems, I made the classic mistake: obsessing over averages. ‘The model averages 500 ms!’ I’d tell myself, feeling good about the numbers. But averages lie. Here’s what I learned the hard way: if every tenth request drags out to 3–4 seconds, that’s what users remember. Not your beautiful average, the frustrating outliers. That’s why I focus on P95 latency. It tells you the time under which 95% of responses complete, and flags the slowest 5% that really define the user experience. P95 isn’t about the middle of the curve; it’s about the tail, where trust gets won or lost.
The best analogy I’ve found is my local coffee shop. Most customers get their drink in under a minute. But every so often, someone waits five minutes for a complicated order. If you’re that unlucky customer, your opinion of the shop isn’t shaped by the average it’s shaped entirely by those five frustrating minutes. In conversational AI, P95 is the same. It’s the difference between a model that feels instant and one that leaves people staring at a blinking cursor, wondering if something broke.
The Latency Waterfall: Where Time Actually Goes
Before I could optimize my models, I needed to understand where the time was really going. The first time I profiled responses, I was surprised by what I found. Every request flowed through the same predictable stages
- Network: Load balancer hops, TLS handshakes, and network round-trips.
- Tokenization: Converting text into tokens. Usually tiny, but with long prompts it adds up.
- Prefill: The first heavy forward pass across the entire prompt, which sets up the KV-cache.
KV-cache: a short-term memory of key/value pairs that lets the model reuse previous computations instead of recalculating everything for each new token. This is what makes decoding much faster after the prefill step.
4. Decode: Generating output tokens one by one, attending over all cached context.
5. De-tokenize and Stream: Turning tokens back into words and streaming them to the client.
Two things stood out immediately (and they surprise most teams I’ve compared notes with):
- Prefill was the hidden bottleneck. I obsessed over decode speed, but prefill alone was burning half a second. That’s where the real fat was hiding.
- TTFT mattered more than total time. I had been measuring end-to-end completion, but users actually judge speed by time-to-first-token. If that first word appears within 300–500 ms, the system feels fast, even if the rest of the text streams in later
The Latency Diet in Practice
After breaking down the latency waterfall, I had one of those moments where everything clicked. The mystery was solved! I could see exactly where my milliseconds were vanishing into thin air. But then reality hit: knowing where the problem is and actually fixing it are two very different things. I’ll be honest, I was expecting some deep technical rabbit holes. Maybe I’d need to hack the inference engine, or dive into CUDA kernels, or learn some obscure optimization nobody talks about. Turns out, I was overthinking it completely. The biggest wins came from changes so simple I actually laughed out loud when I saw the results. We’re talking about optimizations that took minutes to implement but shaved off hundreds of milliseconds. The kind of fixes that make you wonder why you didn’t try them on day one.
Here’s my battle-tested playbook—the stuff that actually works!
1. Prompt Diet: fewer tokens, faster prefill
When I first profiled my system, I was convinced decoding would be the bottleneck. I’d spent days tweaking generation parameters and obsessing over token-per-second rates. Then I actually ran the profiler. The results were humbling: the biggest slowdown was just feeding the model the prompt. I stared at those numbers for a while before it clicked. Before generating a single word, the model has to run the entire prompt* through all its layers. This stage is called prefill, and its cost grows with input length. Because attention scales quadratically, longer prompts hurt more than I’d realized. My carefully crafted 2,000 token prompts were eating 400-500ms before the model even started “thinking.” The fix was embarrassingly simple: shorten the prompt. Not the most exciting optimization, but often the most effective one.
Measuring it
ids = tokenize(prompt, return_tensors="pt").to(device)
t0 = time.perf_counter()
_ = model(**ids, use_cache=True) # running the prefill
print({"tokens_consumed": ids["input_ids"].shape[-1],
"prefill_time": round((time.perf_counter()-t0)*1000, 1)})Here’s a real example I ran
Verbose system prompt (~300 tokens):
You are a very helpful assistant who must carefully follow these important rules:
- Always provide your answers with enough explanation for clarity.
- Be polite, formal, and structured.
- Never skip a step unless explicitly told to do so.
- Please ensure that every answer is factually correct to the best of your ability...
(etc. lots of boilerplate text)
Slimmed-down system prompt (~80 tokens):
You are a helpful assistant.
Rules:
1) Be concise and clear.
2) Use bullet points when listing.
3) If unsure, ask a clarifying question.
4) Cite data if requested.The numbers showed a great positive signs in latency!
Verbose: {“tokens_consumed”: 302, “prefill_time”: 720.4}
Slimmed: {“tokens_consumed”: 81, “prefill_time”: 468.1}
2. Tokenizer Fit: why characters aren’t the right metric
After cleaning up my prompts, I thought I had solved most of the latency issue. Then I noticed something odd: two queries with the same number of characters would have very different response times. That’s when I realized the obvious: models don’t care about characters, they care about tokens. And depending on the tokenizer, the same string can be split into wildly different token counts.
samples = [
"ResetPasswordToken_ABC123_v2",
"Rambo María",
"function doSomethingSuperSpecific(userID) { return true }"
]
for s in samples:
print(s, len(tok(s)["input_ids"]))
Running this made it clear:
- Rambo María → 4 tokens
- doSomethingSuperSpecific → 6 tokens
- ResetPasswordToken_12321_done → 9 tokens
When I tried a tokenizer better tuned for code, the average token count on my inputs dropped by ~12%. Prefill latency dropped almost one-to-one.
Note: You cannot swap tokenizers arbitrarily. The embedding matrix and vocab IDs are learned together.
To change tokenization you must: use a model trained with the better tokenizer, or extend the vocab (resize embeddings) and fine-tune so the new tokens aren’t random vectors.
So, measure first. If fragmentation is bad, either (a) pick a sibling model with a saner tokenizer for your domain, or (b) plan a short fine-tune after adding tokens.
One Quick Note
Tokenizers aren’t universal. They’re language and script specific. A tokenizer tuned for English may explode token counts on, say, Hindi, Chinese, or mixed-script inputs. If your workload is multilingual, measure token counts per language and consider vocab extensions or alternate models.
3. KV-cache Reuse: don’t recompute what you already know
After fixing prompts and tokenization, the biggest latency win I found was surprisingly straightforward: stop recomputing the past.
What’s actually happening
When a model processes your prompt, every transformer layer produces keys and values for each token. These get stored in a KV-cache.
- Prefill: builds the cache for the entire input.
- Decode: uses the cache so each new token only attends to the latest additions, not the whole sequence again.
Without cache reuse in chat, every new user message forces the model to reprocess the full conversation history, hundreds or thousands of tokens before generating the next reply.
How I enabled this KV-cache reuse
system = tokenize(prompt, return_tensors="pt").to(device)
sys_out = model(**system, use_cache=True)
past = sys_out.past_key_values # cache the prompt
turn = tokenize("\nUser: Hello\nAssistant:", return_tensors="pt").to(device)
out = model(input_ids=turn["input_ids"], past_key_values=past, use_cache=True)# Reuse cache for the next turn
past = out.past_key_values # Extending the cache with new tokens
So.. Where is the COST here?
The cost: VRAM
KV-cache size grows linearly with context length × layers × hidden size:
memory ≈ 2 * n_layers * hidden_size * sequence_length * bytes_per_element
- keys + values = 2
- bytes_per_element = 2 for fp16/bf16.
For a 7B model (32 layers, hidden 4096) at 8k tokens: ~4.2 GB just for KV-cache
Practical guardrails
- Eviction: Drop oldest turns when cache exceeds budget
- Summarization: Periodically compress history into a shorter text summary and rebuild cache
- Warm pool: Prefill static prefixes (prompt, tool specs) once, then serve from a warm cache instead of recomputing
- Session stickiness: Keep each user session bound to a single worker cache reuse doesn’t work if requests bounce across servers
4. Speculative & Medusa Decoding: when you can’t parallelize the algorithm, parallelize the guessing
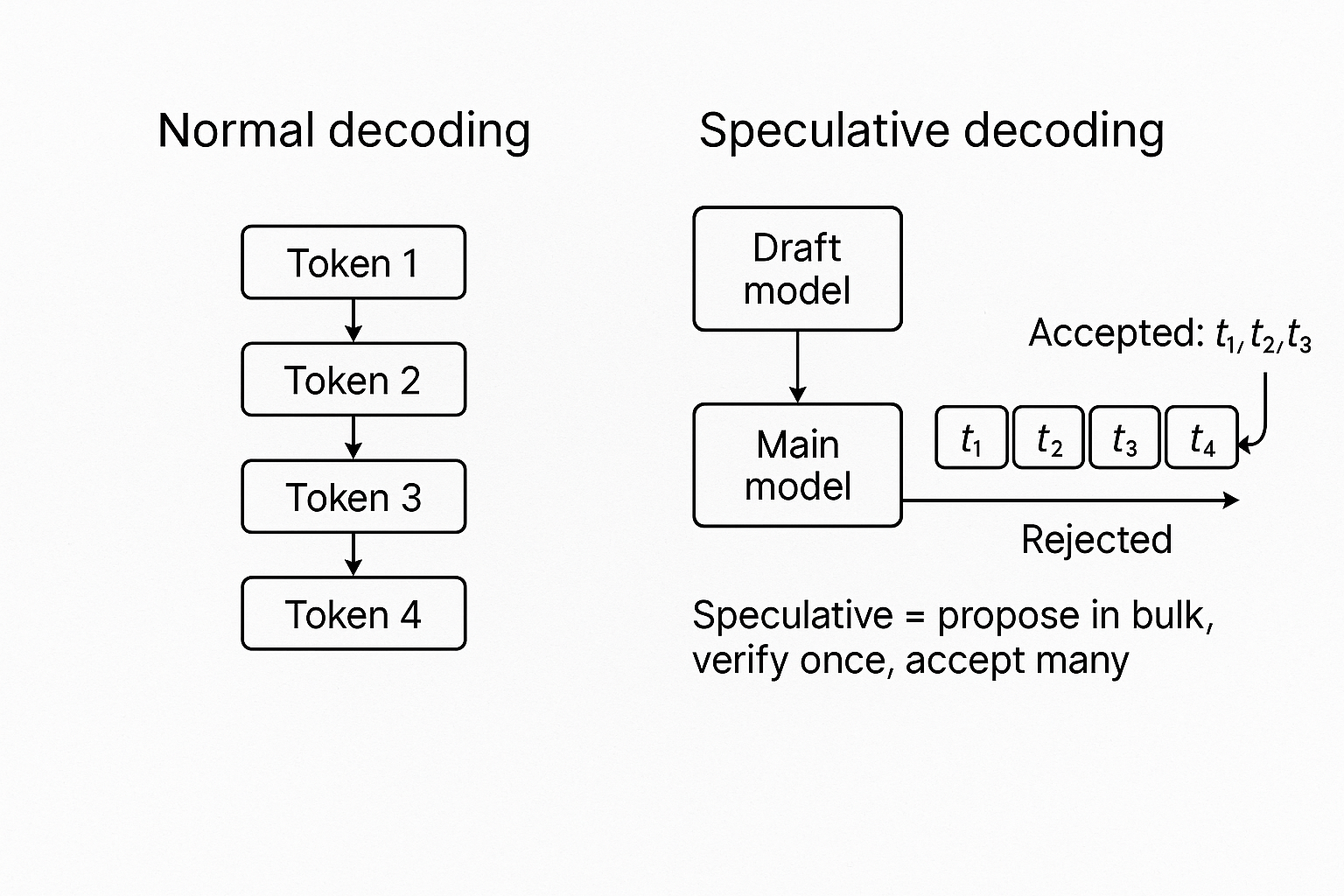
After solving caching, decoding became the next wall. The problem is fundamental: decoding is inherently sequential. The model predicts one token, feeds it back in, predicts the next, and repeats. You Want 1000 tokens? You’re running 1000 sequential decode steps. No batching trick changes that reality. Then I discovered speculative decoding and its variant Medusa decoding, techniques that attack this bottleneck by doing something counterintuitive : guessing multiple steps ahead in parallel.
Speculative Decoding: Draft and Verify
Speculative decoding introduces a two-phase approach:
- Draft phase: A small, fast model proposes multiple tokens (e.g., 4-8 tokens ahead)
- Verify phase: The main model checks all proposals in a single forward pass
- Accept: Keep the longest prefix where both models agree
- Reject: Discard the rest and continue from the last accepted token
Draft model (small): "Thank you for your"
Main model (large): ✓ ✓ ✓ ✗
Accept: "Thank you for" → Continue from thereInstead of 4 sequential steps, you’ve processed them in essentially one verification pass. The key insight: the draft model doesn’t need to be perfect, it just needs to be right often enough. Language has structure and predictability. After “Thank”, the token “you” is highly probable. After “New York”, “City” is likely. The draft exploits this: easy continuations (common phrases, deterministic sequences) get accepted, hard choices (creative writing, technical details) get caught and corrected, and the net result is you skip the sequential bottleneck for 60-70% of tokens. It’s autocomplete for LLM inference propose the obvious, verify in parallel, accept what’s correct.
Medusa Decoding: Self-Speculative Generation
Medusa removes the separate draft model entirely. Instead, it adds multiple prediction heads (small neural network layers attached after the main model’s backbone, each trained to predict tokens at different future positions) to your main model
Input → Model backbone → Head₁ (predicts token t+1)
→ Head₂ (predicts token t+2)
→ Head₃ (predicts token t+3)
→ Head₄ (predicts token t+4)Each head is a lightweight classifier (similar to the model’s final output layer) that shares the backbone’s hidden states but makes independent predictions about future tokens. All predictions happen in one forward pass. The model then verifies its own proposals using a tree-based attention mechanism.
What I saw in practice
When I finally got this working with a 1.3B draft model feeding a 7B main model, the results were pretty satisfying:
- Acceptance rate: around 70% (better than I expected)
- 200-token outputs: nearly 2× faster wall-clock time
- Short answers under 50 tokens: actually got slower due to overhead
But please note it’s most useful when:
- Responses are longer (≥100 tokens),
- Latency matters (chat, search, agents),
- Can afford to run a small “draft” model alongside the big one.
5. Early Exit: stop when you’re already sure
Even after prompt trimming, tokenization fixes, KV-cache, and speculative decoding, I noticed something not every token needed the full weight of the model. Some predictions were obvious long before the final layer finished.
That’s when an interesting observation came.
In a transformer, each layer refines the logits (probabilities of the next token). Each layer is basically another round of “thinking” about the next word. But sometimes, by layer 20, the model is already 99% sure the answer is “green apple” or “apple.” Running 10 more layers rarely changes that; it just burns compute.
Early exit is the idea of saying “good enough” and stopping the forward pass once the model is confident.
probs = torch.softmax(logits[:, -1, :], dim=-1)
entropy = -(probs * (probs.clamp_min(1e-9)).log()).sum()
if entropy.item() < 1.5
stop = True
- Entropy measures uncertainty in the distribution.
- Lower entropy = sharper, more confident.
- If below threshold → exit early for that token
In practice, early exit worked best on short, deterministic tasks things like factual Q&A, SQL or JSON outputs, and classification-style prompts. In those cases, per-token latency dropped by about 20–30% with no real accuracy loss. But when I tried it on long, open-ended completions, the trade-off showed: outputs lost fluency, and the phrasing sometimes felt off. So for me, early exit is a targeted tool, great for structured or predictable outputs, but not something I’d enable for creative text or high-temperature sampling.
6. Streaming: perception is reality
Here’s one of the most important things I realized, total completion time isn’t what makes a system feel slow. What really matters is how long someone stares at a blank screen. This became obvious when I was chasing tiny wins shaving 100 ms off total response time, while the profiler showed 800+ ms before the first token even appeared. From the outside, that just looks like the system is stuck.
The moment everything clicked
I added streaming, and the shift was immediate in perception, not raw numbers. TTFT dropped from 820 ms to 180 ms, while total completion time stayed exactly the same at ~1.7 seconds. What changed was how I experienced the interaction. The moment the first token appeared quickly, the model felt responsive, even though the overall wait didn’t budge. That’s when it hit me: perception is reality in latency.
Streaming is about delivering tokens as soon as they’re generated instead of waiting for the full response
Using Hugging Face’s TextIteratorStreamer, I started pushing tokens out the moment they were ready
from transformers import TextIteratorStreamer
import time, threading
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
gen_config = dict(**inputs, max_new_tokens=100, streamer=streamer, use_cache=True)
threading.Thread(target=model.generate, kwargs=gen_config).start()
start_time = time.perf_counter(); first = True
for chunk in streamer:
if first:
print("Time to first token :", round((time.perf_counter()-start_time)*1000, 1), "ms")
first = False
print(chunk, end="", flush=True)
Interesting things to note
- Server-side: proxies like Nginx or Cloudflare may buffer responses, delaying the first token. Disable buffering or use chunked transfer.
- Client-side: render tokens as they arrive, don’t wait to display until the response ends.
- Always log TTFT separately from total time, they impact user perception differently.
So… What I Learned
Building a fast LLM system wasn’t about one breakthrough trick. It was about fixing a series of small inefficiencies that quietly added up. Each technique shaved latency in its own way
| Technique | Latency Win | Where it helps most |
| Prompt Diet | Cuts 200–400 ms from prefill | Any model, especially with long prompts |
| Tokenizer Fit | ~12% fewer tokens → faster prefill | Domain-specific text/code |
| KV-cache Reuse | Avoids reprocessing old tokens | Multi-turn chat, agent loops |
| Speculative / Medusa Decoding | Up to 2× faster on long output | ≥100-token responses |
| Early Exit | 20–30% faster per token | Deterministic / structured tasks |
| Streaming | TTFT drop 820 ms → 180 ms | Perceived speed in chat/UI |
None of this required great hardware or model surgery, just systematic measurement and targeted fixes.
The biggest lesson? Measure first, optimize second. Without breaking down the latency waterfall, I would have spent weeks tuning the wrong knobs.
One More Thing: What About Reasoning Models?
Everything I’ve covered here works great for “chatty” LLMs, the kind where you want snappy back-and-forth in conversations or quick agent responses. But reasoning models are a different beast. With multi-step problem solving, chain-of-thought planning, or tool use, that extra latency isn’t always “fat to trim.” Sometimes those seconds represent genuine thinking more steps, deeper analysis, verification loops. The delay is part of what makes them smart. Users also expect it. When I say “let me think through this step by step,” people are fine with a pause if it feels purposeful.
This opens up a fascinating new question: How do you make reasoning models feel fast without breaking the very deliberation that makes them accurate? That’s a challenge I’m still working on and probably worth its own deep dive. If I get a breakthrough you might see another blog, something like, “Latency Isn’t Always the Enemy: Designing for Reasoning Models”😜
It’s a reminder that not all latency is created equal. Sometimes slow thinking is exactly what you want.
Resources
- https://developer.nvidia.com/blog/mastering-llm-techniques-inference-optimization/
- https://www.digitalocean.com/community/tutorials/llm-inference-optimization
- https://huggingface.co/docs/transformers/main/en/main_classes/text_generation
- https://medium.com/foundation-models-deep-dive/speculative-decoding-for-faster-llms-55353785e4d7
- https://artificialanalysis.ai/..

