
It is a deceptively simple construct — an LLM(Large language model) is trained on a huge amount of text data to understand language and generate new text that reads naturally. The model is then able to execute simple tasks like completing a sentence “The cat sat on the…” with the word “mat”. Or one can even generate a piece of text such as a haiku to a prompt like “Here’s a haiku:”
But it gets even cooler! Once an LLM learns a language, you can use it for all kinds of tasks. It can answer questions, translate between languages, summarize text, write speeches, have conversations generate code and more. The possibilities are endless!
LLMs are getting shockingly good at understanding language and generating coherent paragraphs, stories and conversations. Models are now capable of abstracting higher-level information representations akin to moving from left-brain tasks to right-brain tasks which includes understanding different concepts and the ability to compose them in a way that makes sense (statistically).
First-level concepts for LLM are tokens which may mean different things based on the context, for example, an apple can either be a fruit or a computer manufacturer based on context. This is higher-level knowledge/concept based on information the LLM has been trained on.
In contrast with classical machine learning models, it has the capability to hallucinate and not go strictly by logic.
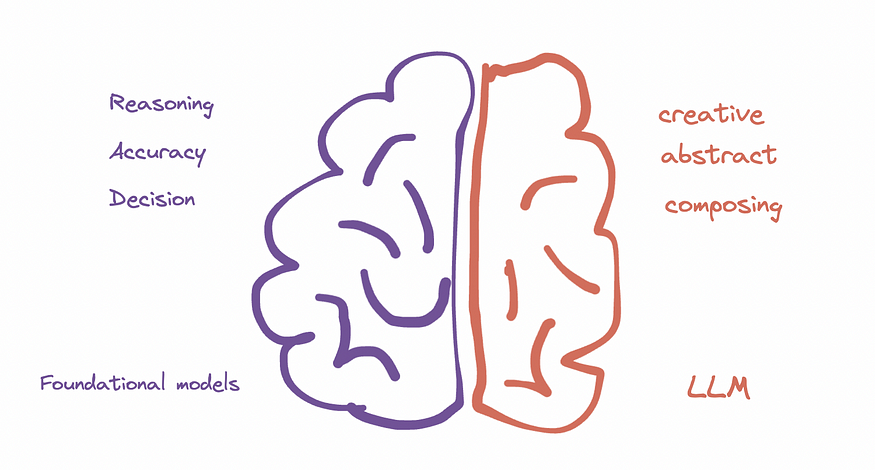
Possibilities and constraints
LLM is not a panacea; it has its limitations. There are things that it cannot do such as
- Human level comprehension i.e., truly understand the underlying concept
- Avoid biased, harmful and untrustworthy responses
- Match human creativity
- Analytical, algebraic and other calculations and mathematical reasoning
- Physical world reasoning: it lacks experiential knowledge about physics, objects and their interaction with the environment.
- Transferring knowledge between tasks
- Learning from a small amount of data
LLM is good at learning from massive amounts of information and making inferences about the next in sequence for a given context. LLM can be generalized to non-textual information too such as images/video, audio etc. Transformer-based audio-to-audio or audio-to-text would learn the composition of constructs in terms of audio signals instead of text symbols.
Given its capabilities, here are the areas/streams where LLM can excel:
- Assistants and interactive conversational bots
- Content generation and summarization
- Machine translation, multilingual support
- Context-aware search
- Knowledge management
- Question answering, language-based search
- Customer satisfaction and product improvement — Sentiment Analysis, Text classification, Personalisation, and Recommendation.
- Data transformations
Now the question arises, what does all this translate into for businesses? How can we adopt LLM to aid decision making and other processes across different functions within an organization?
Let’s quickly take a look at structure and usage in order to assess the possible use for given business.
Structure and Usage
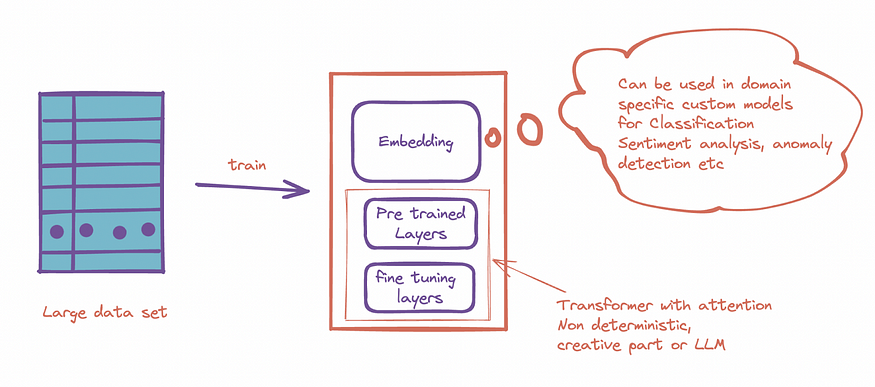
Model inference involves 2 stages:
- Projecting the input to tensor format — this involves encoding and embedding. Output from this stage itself can be used for many use cases.
- Inference — This makes output prediction based on the given context. It is heavily dependent on training data and the format of training data.
Inference behaviour can be customized by changing weights in layers or input. Typical methods to tweak model output for specific business use-case are:
- As is
- Instruction based tuning
- Fine-tuning
- Pre Training
As Is
This is suitable for POCs and certain use cases that we will identify later in this blog. The important thing to note is that it involves no additional customization, training data or effort.
Instruction based tuning
- Less effort in tuning, no training required, one-shot learning.
- Example: for given product review rate the product aesthetics in range of 1 to 5 review: “`I liked the … but .. “`. Be concise and output only rating in json format given“`{“rating”:<rating>}“`
{“rating”: 2}
- Limited by context length
Pre-Training and Fine-tuning
Pre-training involves training the model on a huge amount of text data in an unsupervised manner. This allows the model to learn general language representations and knowledge that can then be applied to downstream tasks. Once the model is pre-trained, it is then fine-tuned on specific tasks using labeled data.
Fine-tuning involves taking the pre-trained model and optimizing its weights for a particular task using smaller amounts of task-specific data. Only a small portion of the model’s weights are updated during fine-tuning while most of the pre-trained weights remain intact.
This two-step process of pre-training and fine-tuning has several advantages:
1. It allows the model to learn general linguistic and domain knowledge from large unlabelled datasets, which would be impossible to annotate for specific tasks.
2. The pre-trained representations capture useful features that can then be adapted for multiple downstream tasks achieving good performance with relatively little labelled data.
3. It is more computationally efficient since the costly pre-training step only needs to be done once after which the same model can be fine-tuned for different tasks.
4. The pre-trained model can act as a good starting point allowing fine-tuning to converge faster than training from scratch.
To summarize, pre-training large language models on general text data allows them to acquire broad knowledge that can then be specialized for specific tasks through fine-tuning on smaller labelled datasets. This two-step process is key to the scaling and versatility of LLMs for various applications.
Here is a quick decision guide to decide on the approach:
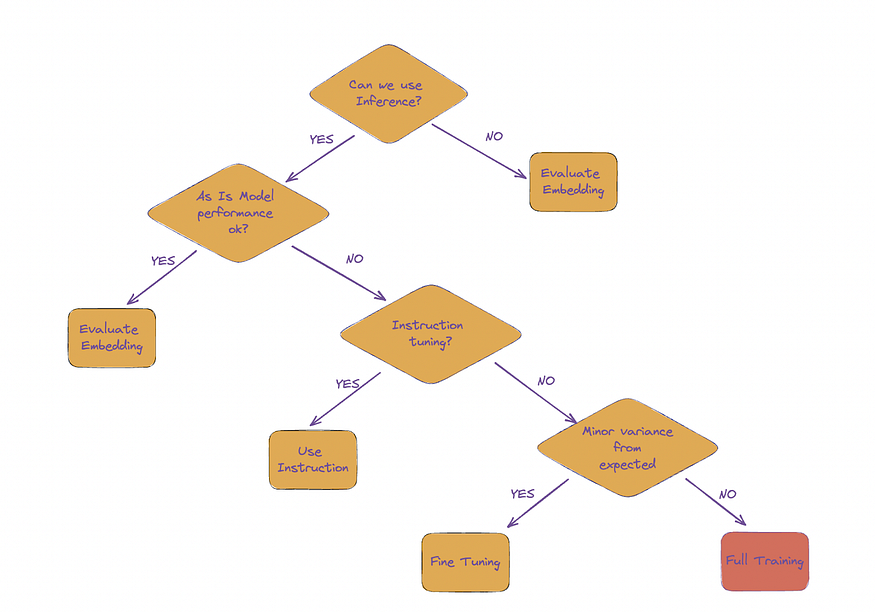
LLM adoption checklist
LLM usage can be determined by multiple factors such as usage context, type of task etc. Here are some characteristics that affect efficiency of LLM adoption:
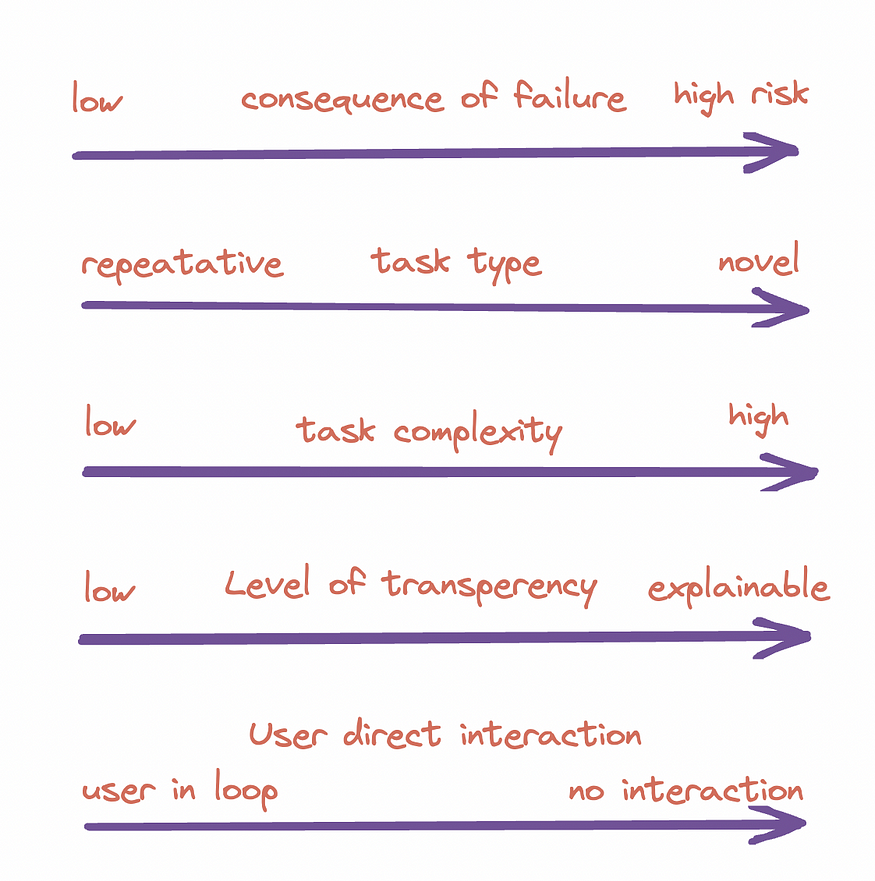
If while rating across the above dimensions, one or more characteristics on the extreme right-hand side are identified, it should be treated as an amber flag for adoption of LLM in production. If you have more than three, it is a definitive red flag for implementation and might need a critical review of the use case.
Other factors to consider:
- Regulatory or legal constraints — Driving or assistance in driving, for example, may or may not be allowed. Similarly, constraints in medical and legal fields might need to be considered.
- The novelty of the scenario causing the error — Criticality of error due to new variants of unseen input, medical diagnosis, legal brief etc might warrant human in-loop verification or approval.
- Repeatable results given the same context
- Not required: Multiple possible outcomes are valid and if the system produces different responses or results, it is still valid. Example: code explanation, summary.
- Similar: Variance is okay however the overall approach and steps are expected to be consistent. Examples: blogs, articles, chat responses, and advice.
- Same: Diagnosis, legal references in advice, project plan, cost projections etc. Some artefacts can support other plans or outcomes, LLMs can change the approach when small underlying details change.
- Cost estimate of usage — Review usage of inference per user per activity. For example, blog generation is 1:many user reads.
- Low: Blog, article etc generated once and read many times, effective LLM usage is relatively less.
- Medium: One-to-one scale of LLM usage with number of users. For example, code completion, occasional intervention by LLM-generated content etc.
- High: Use-case might heavily depend upon multiple LLM capabilities in usage. For example, interactive assessment for students’ learning journey, suggestions, response grading, generating study path etc.
Available options
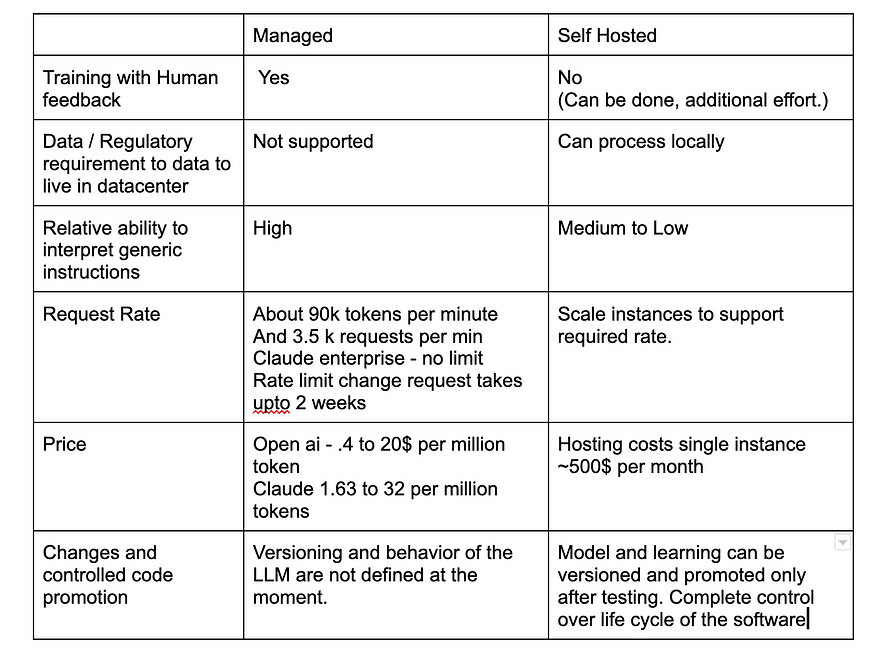
Since cost is an important factor, here are available options that can help estimate the usage cost:
Hosted
- Openai
- Claude — enterprise licensing available.
- Baseplate
- Adept (waitlist)
Self-hosted
- gpt4all , alpaca, vicuna and many other training frameworks and wrapper for different languages available.
- gpt2 based minimalistic models with custom data
Recommended strategies for capitalizing on LLMs
Evaluate and adopt AI-driven solutions
- Assess current software solutions and identify areas of improvement
- Consider the benefits and risks of AI integration
- Pilot and iterate on AI-driven solutions
Build safeguards from the start
- Define and control accuracy, methods for detecting factual errors
- Allow human oversight or intervention
- Human approvals can be used for crucial outputs
- Monitor model/data drifts or anomalies for a complete takeover of critical systems
Prioritize domain-specific training
- Custom training might need large annotated samples
- Fine-tuning can be the first step for domain-specific use-cases
Start small and evolve, Continuous Model maintenance and delivery
- Start small use cases, POC and experiment as an alternative to the main flow using AB testing or as an alternative offering.
- Iterate faster with feedback and tuning as part of the solution promotion cycle.
Overall, businesses should take a two-pronged approach to adopt large language models into their operations. First, they should identify core areas where even a surface-level application of LLMs can improve accuracy and productivity such as using automated speech recognition to enhance customer service call routing or applying natural language processing to analyze customer feedback at scale.
Second, and more ambitiously, businesses should explore experimental ways of leveraging the power of LLMs for step-change improvements. This could include deploying conversational agents that provide an engaging and dynamic user experience, generating creative marketing content tailored to audience interests using natural language generation, or building intelligent process automation flows that adapt to different contexts. The companies that recognize LLMs’ potential to not just optimize existing processes but reinvent them all together will be poised to lead their industries. Success with LLMs requires going beyond pilot programs and piecemeal solutions to pursue meaningful, real-world applications at scale and developing tailored implementations for a given business context.

