

In the ever-evolving landscape of information retrieval and Large Language Models (LLMs), Retrieval-Augmented Generation (RAG) is becoming a de facto mechanism to quickly answer questions across a broad range of topics. However, the responses can often suffer from inaccuracies when they predominantly rely on extracting chunks of information with keyword matching only.
What is Hierarchical RAG?
Hierarchical RAG (HRAG) is a technique to improve the accuracy and relevance of responses.
HRAG builds on traditional RAG by using a structured method to organize and find information at different levels, instead of pulling information from one large collection of documents like standard RAG.
HRAG arranges data into layers or categories. This makes it easier to search and find relevant details with more accuracy and context.
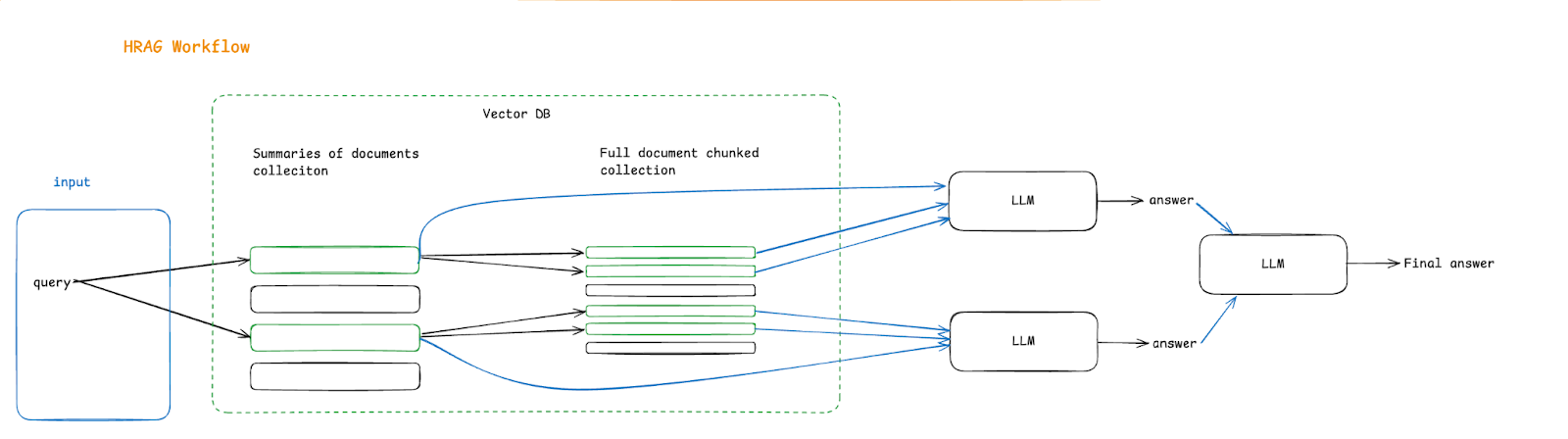
For instance, consider a hierarchical system where we have a summary of all the documents, and when a query comes in, it is first searched inside summaries of the documents. Based on the best matches, the content is further used for searching in the actual chunks of the document. Subsequently, both summary and actual chunks will be sent to LLM with a query per document so that LLM is equipped to make better decisions using the summary of the document along with the actual chunk.
How Does HRAG Work?
HRAG operates through a two-step retrieval process:
Top-Level Selection: The model first queries a broader index to identify the most relevant categories or sections. This layer includes large document titles and main topics like Summary.
Granular Retrieval: Once a top-level section is selected, the model performs a more focused search to find specific information or sub-documents.
This multi-tiered approach mimics how humans scan a table of contents or indexes before narrowing their search to specific chapters or pages.
Step-by-Step Code Guide for Trying Out Hierarchical RAG
Assuming you have set up a basic RAG system as outlined in this guide, here is how you can extend it to implement HRAG with minimal Python code:
# --------------------
# Assume setup steps are completed here:
# - Vector databases are created (e.g., Milvus or ChromaDB) for:
# 1. Summaries of documents collection
# 2. Full document chunked collection
# - Environment variables like OpenAI API keys are configured
# - Necessary Python libraries are installed
# --------------------
# Core logic for RAG and HRAG workflows
class RAG:
def __init__(self, vector_db: Milvus):
"""Initialize RAG with a vector database."""
self.vector_db = vector_db
self.llm = OpenAI(model="gpt-4")
self.qa_chain = RetrievalQA(retriever=vector_db.as_retriever(), llm=self.llm)
def get_response(self, query: str) -> str:
"""Get response for the query."""
return self.qa_chain.run(query)
class HRAG:
def __init__(self, summary_vector_db: Milvus, full_vector_db: FAISS):
"""Initialize HRAG with two vector databases."""
self.summary_vector_db = summary_vector_db
self.full_vector_db = full_vector_db
self.llm = OpenAI(model="gpt-4")
async def get_context(self, query: str, collection_name: str, summary_collection_name: str) -> List[RAGContext]:
"""
Gets the context based on the query from vector DB.
Args:
query:
collection_name:
summary_collection_name:
Returns:
list of RAGContext
class RAGContext(BaseModel):
'Schema for relevant chunks for a RAG method.'
text: str
file_name: str
file_id: str
summary: str | None = None
"""
result = await self.query(
query,
summary_collection_name,
output_fields=["file_name", "text"]
)
file_summaries = {
record["entity"]["file_name"]: record["entity"]["text"]
for record in sorted(result[0], key=lambda x: x["distance"])
}
query_filter: str = f"file_name in {list(file_summaries.keys())}"
output_fields = ["file_name", "text", "file_id"]
final_result: list[list[dict[Any, Any]]] = await self.query(query, collection_name, output_fields, query_filter)
contexts = []
for record in sorted(final_result[0], key=lambda x: x["distance"]):
contexts.append(RAGContext(
file_name=record["entity"]["file_name"],
file_id=record["entity"]["file_id"],
text=record["entity"]["text"],
summary=file_summaries[record["entity"]["file_name"]]
))
return contexts
async def get_response(self, query: str, collection_name: str, summary_collection_name: str) -> str:
"""Get response for the query by combining both databases."""
# Step 1: Retrieve hierarchical contexts
contexts = await self.get_context(query, collection_name, summary_collection_name)
# Step 2: Format input for the LLM
formatted_context = "\n".join([f"File: {ctx.file_name}\nSummary: {ctx.summary}\nText: {ctx.text}" for ctx in contexts])
input_prompt = f"Query: {query}\nContext:\n{formatted_context}\nAnswer:"
# Step 3: Get response from LLM
return self.llm(input_prompt)Benefits of Hierarchical RAG
Following are the benefits of a Hierarchical RAG:
Enhanced Contextual Relevance: By searching within predefined sections, Hierarchical RAG can provide answers that are more contextually relevant and detailed.
Efficient Search: This method reduces the search space for specific queries, improving the speed of retrieval and response generation.
Why is it needed?
Hierarchical RAG is particularly useful in scenarios where information is extensive and highly structured. Here are some examples where it can be used:
Technical Manuals: Complex technical documents, such as those in engineering or software development, can be navigated more efficiently using a hierarchical retrieval system.
Academic Research: For academic institutions or researchers managing vast amounts of papers and references, Hierarchical RAG can streamline the search process by focusing retrieval on specific research areas or study findings.
Any document with structured or unstructured data or information
Challenges with HRAG
While HRAG seems very promising in terms of context-aware retrieval and results in better responses to queries, it does so by trading off the overall performance of queries:
Alignment with Data Structure: The effectiveness of the retrieval depends on how well the hierarchical structure aligns with the actual content. Poorly designed hierarchies can result in suboptimal retrieval performance.
Higher Computational Load: Although vector retrieval is a very fast and efficient process, the multi-step retrieval process can increase the computational burden, especially when processing a high volume of queries simultaneously.
Conclusion
As the demand for precise and context-aware information retrieval grows, HRAG remains a promising approach to include in the toolkit. By leveraging a layered approach to search and generation, this advanced technique bridges the gap between broad information retrieval and targeted, context-rich answers.

