

Introduction
Ensuring data quality is crucial for building reliable ML models. In this guide, we integrate data quality checks into an ML pipeline using DVC (Data Version Control) to enable versioning, tracking, and automated validation of datasets before model training.
ML Pipelines
Machine Learning pipelines automate the end-to-end ML process, handling everything from data ingestion to model deployment. They help break down complex workflows into manageable stages.
Important stages of the pipeline:
Data Quality check
Data preprocessing
Feature engineering
Model training and evaluation
Model serving and monitoring
This article focuses on implementing the Data Quality Check stage within a basic ML pipeline using DVC.
Setting up ML Pipeline with DVC
We demonstrate how to organize and version a sentiment analysis dataset using DVC. The dataset includes features such as title and text, which help determine sentiment.

Using DVC, we track dataset versions, manage changes efficiently, and ensure reproducibility. The next steps define the pipeline stages such as data preprocessing, feature engineering, model training, and evaluation.
Data Preprocessing
The XML-formatted dataset is split into training and test sets based on parameters defined in params.yaml. The extracted text is cleaned, titles and body text are merged, and data is split based on a predefined ratio.
prepare:
split: 0.3
seed: 20170428
featurize:
max_features: 100
ngrams: 1
train:
seed: 20170428
n_est: 42
min_split: 0.01Feature Engineering
Raw text is transformed into numerical representations using Bag of Words (BoW) and TF-IDF (Term Frequency-Inverse Document Frequency) as defined in the params.yaml file. Additionally, other feature extraction methods such as embeddings and hand-crafted features can be used:
Embeddings (optional): Word2Vec, GloVe, or Transformer-based embeddings (BERT) can capture semantic relationships between words.
Hand-crafted Features (optional): Sentiment scores, part-of-speech tags, and domain-specific metadata can enrich the feature set.
Feature matrices are saved as sparse .pkl files to ensure consistent feature extraction.
Training the Model
A Random Forest classifier is trained using the feature matrix. Parameters such as the number of trees and minimum samples per split are loaded from params.yaml. The trained model is stored as a .pkl file for future inference.
Evaluating the Model
Model evaluation is performed using scikit-learn metrics and DVCLive. Key performance metrics like ROC AUC and average precision are logged. Evaluation results, including plots (ROC, precision-recall, confusion matrix, and feature importance), are stored in the eval/ directory.
Integrate Data Quality Checks into the Pipeline
To ensure data integrity, explicit data quality check scripts are created. These scripts track input data integrity and detect drift in an XML dataset versioned with DVC using Evidently AI.
Data Quality Check: The script validates the integrity of the current dataset.
Drift Detection: It compares reference (v2) and current (v3) dataset versions, loads them using DVC, and processes the XML data into a Pandas DataFrame.
Drift Metrics Calculation: Evidently’s DataDriftPreset computes drift metrics such as – Total columns, Drifted columns, Drift share, and Dataset drift status.
Logging with DVCLive: Key drift metrics are logged using DVCLive for tracking and visualization.
Impact Analysis: A summary of drifted columns and their potential impact is generated.
Data Quality Check in the DVC Pipeline
Separate Data Quality Check Stage: Data quality checks are incorporated as a distinct stage in the DVC pipeline. The purpose is to flag bad data early so that we can stop the pipeline and fix the underlying root cause. In the sentiment dataset mentioned above, it may happen that the data now contains reviews in other languages, dialects, regional variations in meaning of the same word. If the model is run without any checks, the quality of results will degrade substantially.
Quality vs. Drift Detection:
Data quality checks operate on the current dataset and do not require reference data.
Drift detection requires reference data to compare against previous versions. For the sentiment dataset mentioned above, an example would be the addition of neutral sentiment in addition to positive/negative sentiment.
Leveraging DVC Versioning: Different versions of the dataset are loaded using git commit tags and the dvc.api.open() feature. This ensures that the data quality metrics are always in-line with the corresponding datasets providing full reproducibility inclusive of the quality metrics.
Quality Reports: Comprehensive reports ensure that only validated data is used in downstream processes.
Orchestrating ML Pipelines using DVC
The pipeline stages are defined in dvc.yaml, specifying dependencies, commands, outputs, and parameters.
stages:
quality:
cmd: python src/quality_check.py
deps:
- data/data.xml
- src/quality_check.py
outs:
- Data_Quality_Report/
prepare:
cmd: python src/prepare.py data/data.xml
deps:
- data/data.xml
- Data_Quality_Report/
- src/prepare.py
params:
- prepare.seed
- prepare.split
outs:
- data/prepared
featurize:
cmd: python src/featurization.py data/prepared data/features
deps:
- data/prepared
- src/featurization.py
params:
- featurize.max_features
- featurize.ngrams
outs:
- data/features
train:
cmd: python src/train.py data/features model.pkl
deps:
- data/features
- src/train.py
params:
- train.min_split
- train.n_est
- train.seed
outs:
- model.pkl
evaluate:
cmd: python src/evaluate.py model.pkl data/features
deps:
- data/features
- model.pkl
outs:
- eval/
metrics:
- eval/metrics.json
- Data_Quality_Report/metrics.json
plots:
- dvclive/plots/metrics:
x: step
- eval/plots/images
- eval/plots/sklearn/roc/train.json:
template: simple
x: fpr
y: tpr
title: Receiver operating characteristic (ROC)
x_label: False Positive Rate
y_label: True Positive Rate
- Data_Quality_Report/plots/metrics:
x: stepManaging Dependencies and Tracking Changes
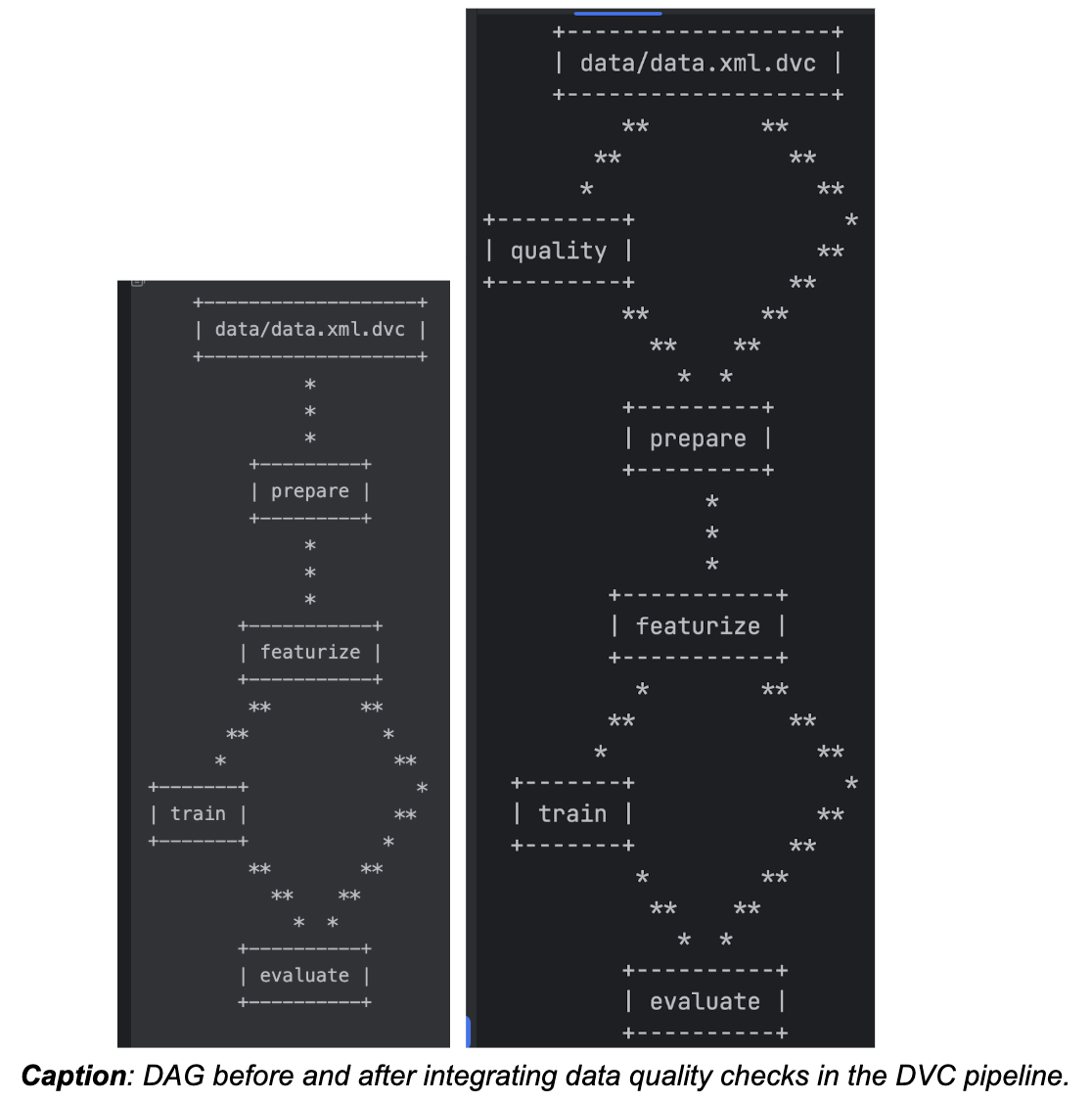
dvc dag visualizes pipeline dependencies in a Directed Acyclic Graph (DAG).
dvc status checks the data and the stages of the pipeline, finds whether the data or pipeline is up to date or has changed and needs a re-run. DVC captures “build requirements” (stage dependencies) and caches the pipeline’s outputs along the way to track changes.
dvc repro reproduces the pipeline completely or partially by running the stages in the dvc.yaml file.
DAG Before and After Integrating Data Quality Checks
Before integrating data quality checks, the prepare stage directly depends on data.xml.dvc. After integration, it also depends on the quality stage, ensuring data is preprocessed only if it meets quality standards.
Conclusion
Integrating data quality checks into an ML pipeline ensures reliable, reproducible models. Using DVC, we track data integrity, monitor drift, and automate quality assurance, making ML workflows more robust and efficient.
This work is done in collaboration with Anay, Ajinkya, Harshad, PV, and Sanket.

