
Containers have revolutionised the way we develop, deploy, and manage applications. They offer lightweight, portable environments that encapsulate everything an application needs to run, making it easier to build, ship, and run software across different computing environments. But have you ever wondered how containers achieve such efficiency and isolation? In this post, we’ll take a deep dive into the internals of containers, exploring their implementation, resource limitations, and isolation mechanisms.

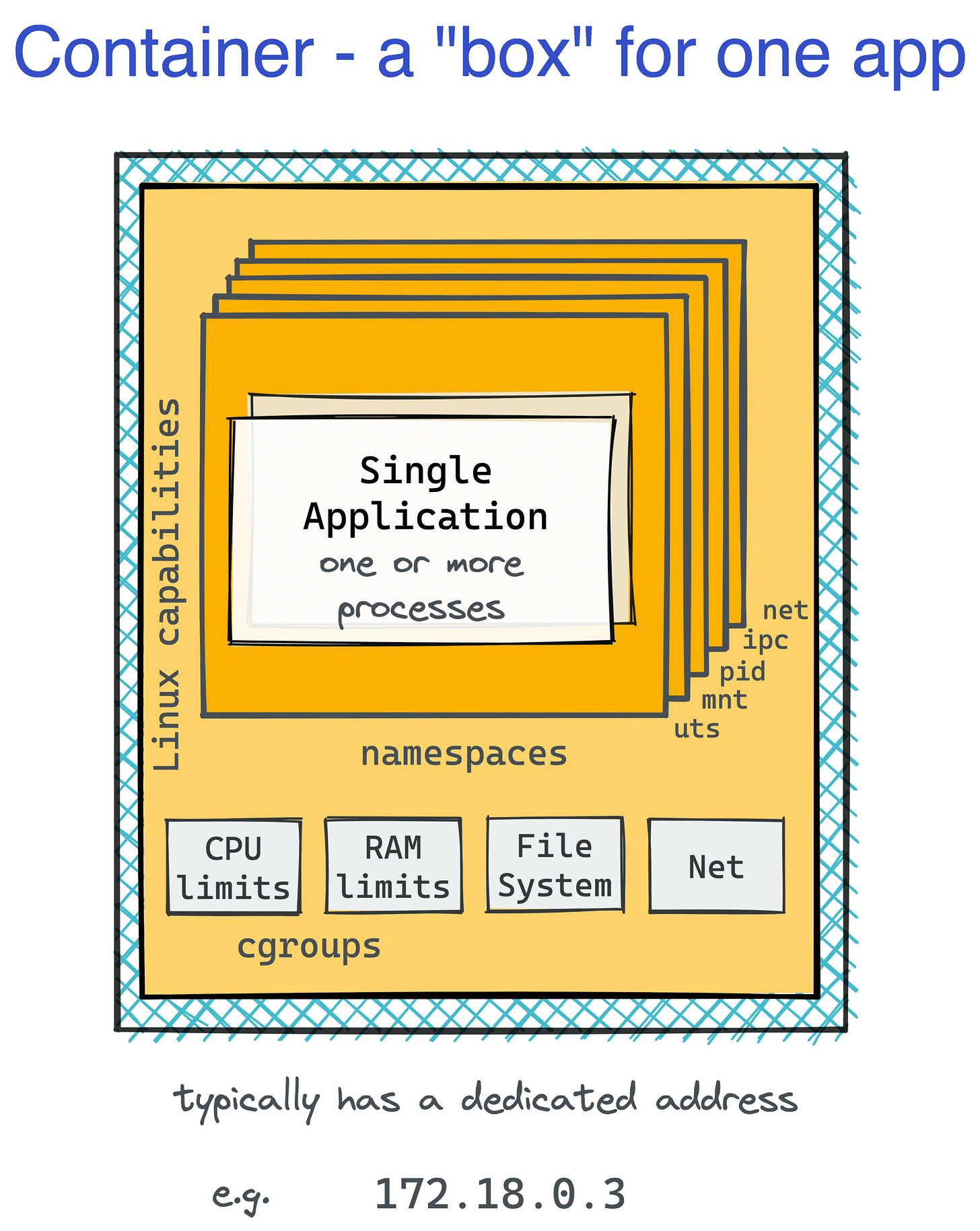
Containers are implemented using a combination of Linux kernel features, primarily namespaces and control groups (cgroups).
Namespaces in Linux:
Let’s look at what Wikipedia says about Namespaces,
Namespaces are a feature of the Linux kernel that partitions kernel resources such that one set of processes sees one set of resources while another set of processes sees a different set of resources.
Namespaces lets you isolate the processes from each other. A namespace wraps a global system resource in an abstraction that makes it appear to the processes within the namespace that they have their own isolated instance of the global resource. Changes to the global resource are visible to other processes that are members of the namespace but are invisible to other processes.
Types of Namespaces in Linux:
User namespace: lets you have your own userIDs and groupIDs within the namespace. A process can have root privilege within its user namespace without having it on other namespaces.
Process ID (PID) namespace: assigns a set of PIDs to processes that are independent of the PIDs in other namespaces. The first process created in a new namespace has PID 1 and child processes are assigned subsequent PIDs. If a child process is created with its own PID namespace, it has PID 1 in that namespace as well as its PID in the parent process’ namespace.
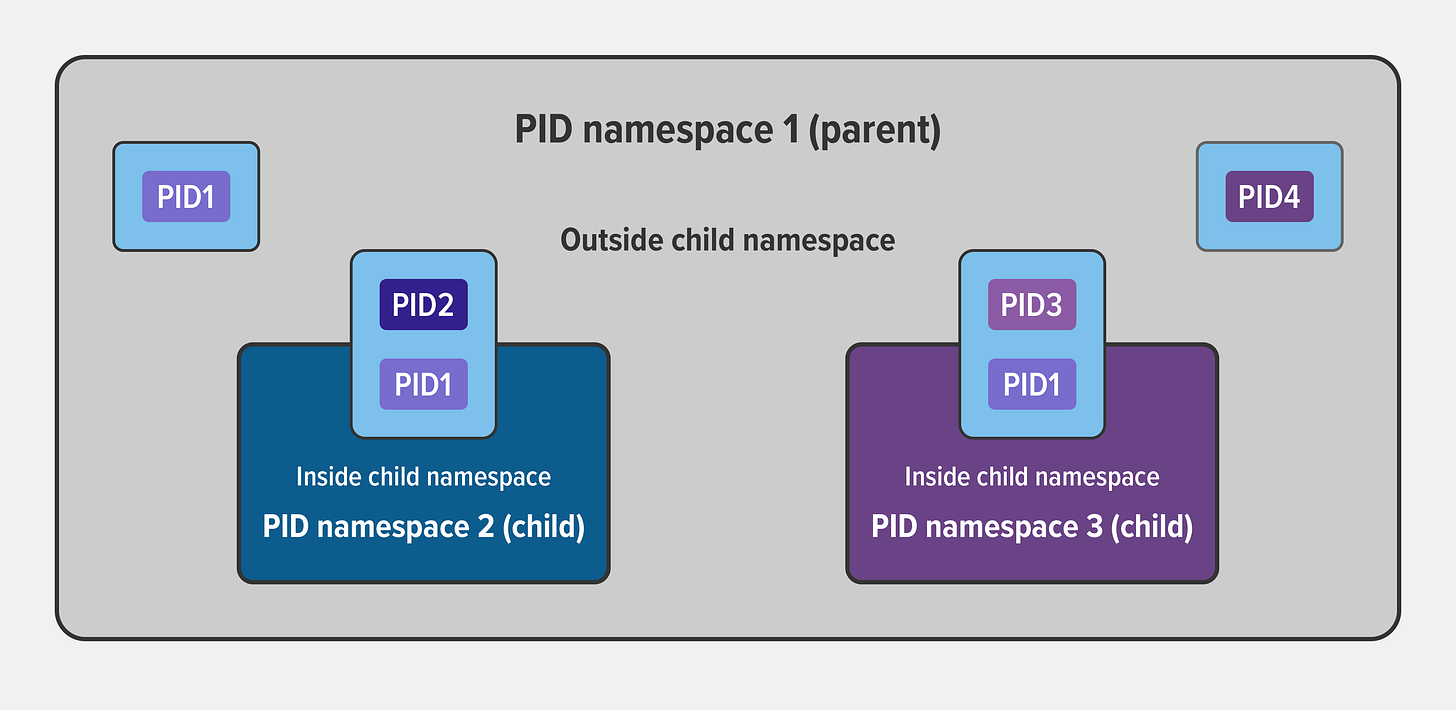

Credits: Nginx Blogs
Network namespace: lets you have an independent network stack: its own private routing table, set of IP addresses, socket listing, connection tracking table, firewall, and other network‑related resources.
Mount namespace: It allows you to have an independent list of mount points seen by the processes in the namespace. This means that you can mount and unmount filesystems in a mount namespace without affecting the host filesystem.
Interprocess communication (IPC) namespace: has its own IPC resources, allowing multiple multiple processes within the same namespaces to perform interprocess communication and message passing.
UNIX Time‑Sharing (UTS) namespace: it allows a single system to appear to have different host and domain names for different processes.
Cgroup Namespace: Cgroup namespaces virtualize the view of a process’s cgroups. This is different from Cgroup itself. You can read more about cgroup later in this post.
Time Namespace: It allows for per-namespace offsets to the system monotonic and boot-time clocks. It is commonly used to change the date/time within a container and adjust clocks after restoring from a checkpoint or snapshot.
ToolKits like docker, LXC, etc use the mix of the above namespaces to create an isolated environment for each container to simulate that each runs on its own hardware.
Cgroups in Linux:
Cgroups, or control groups, are a kernel feature used to manage and limit the system resources consumed by processes. They allow administrators to allocate resources such as CPU, memory, disk I/O, and network bandwidth to specific processes or groups of processes. By using cgroups, containers can enforce resource constraints, preventing one container from monopolizing system resources and causing performance issues. Also, resource utilization can be monitored at the cgroup level which allows efficient usage and the right resource allocation for each cgroup.
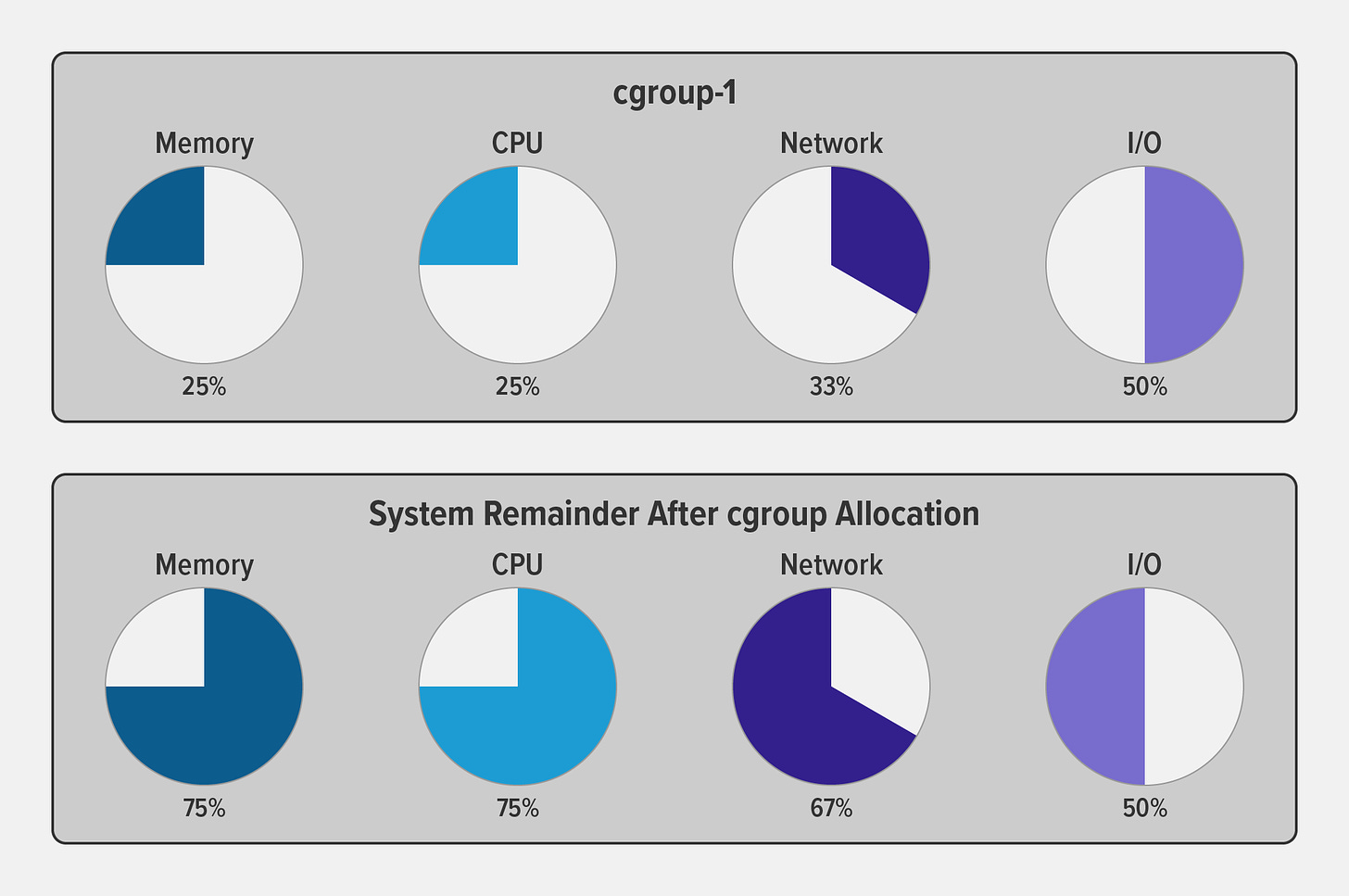
Credits: Nginx blogs
Bonus Tip: You can use Cgroup to restrict the number of processes that a container can spin up. This will avoid the common Denial of attack called the Fore bomb.
Containers and Platform Compatibility:
If containers use Linux-specific features like namespaces and cgroups, then how do they run on other operating systems like Windows and Mac? Yes, You cannot run containers natively on Windows and macOS, which have different kernel architectures. Instead, Toolkits utilizes virtualization techniques that run a lightweight Linux VM to host Docker containers.
But there is a catch, over years there have been multiple works done by these operating systems to make the user’s life easier. At this point, windows allow running other Windows images natively without virtualization. You can find more details about that here.
SideCars in Kubernetes:
While I was going through the internals of containers, I got this interesting question,
if containers are running in an isolated environment, how init containers and sidecar containers in Kubernetes can access each other through localhost?
Turns out the answer is related to what you read so far.
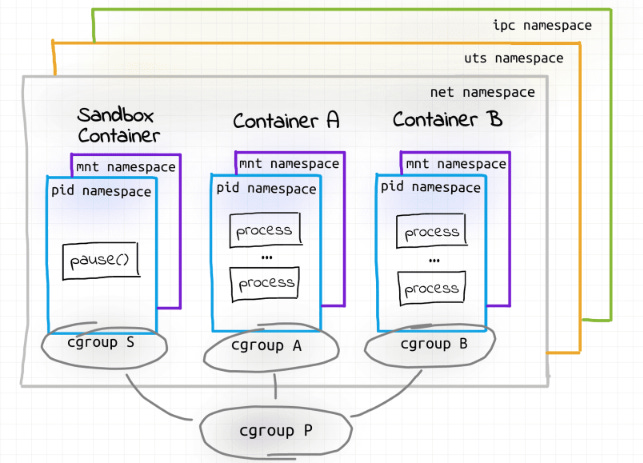
In Kubernetes, the smallest individual deployment is a pod which can have multiple containers running as one logical unit. Understanding why Kubernetes has broken the “One process per container” philosophy is beyond the scope of this blog.
Kubernetes implemented this feature by allowing the containers to share the namespaces among the containers. By default, init containers or sidecar containers share the IPC, network and UTS namespace. A PID namespace can be configured to be shared. Whereas mount and user namespaces are not shared among the containers to allow the containers to have their own filesystem and user groups.
Containers have become an integral part of modern software development and deployment pipelines, thanks to their efficient resource utilization and isolation capabilities. By understanding the internals of containers, including namespaces, cgroups, and sidecars, developers and administrators can better optimize and secure their containerized applications for a variety of use cases. Whether you’re deploying microservices at scale or experimenting with containerized development workflows, a solid grasp of container internals is essential for success in today’s cloud-native landscape.

