Written by: Niranjan Ingale
Table of contents
- What is a Data Platform, Spark & DBT
- Defining the Scope
- Airport Insights: Example of a common analytics use case
- Comparison between Spark & DBT for developing an analytics use case
- Taxi trip duration prediction: Example of developing a model for batch and real-time prediction
- Comparison between Spark & DBT for developing a data science use case
- Push of tech giants towards expanding the use of serverless data warehouses beyond conventional OLAP
What is a Data Platform, Spark & DBT: Let’s start with some definitions
Data Platform: A data platform is a comprehensive infrastructure that facilitates the ingestion, storage, processing, analysis, and management of data across an organization. e.g. Ada By Talon.
Data Build Tool: DBT is a SQL-first transformation workflow that lets teams quickly and collaboratively deploy analytics code following software engineering best practices like modularity, portability, CI/CD, and documentation such that anyone on the data team can safely contribute to production-grade data pipelines.
Apache Spark : Apache Spark is a multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters.
Right away it’s evident that both spark & DBT are tools that can play a role in the development of a data platform yet they differ.
Relatively speaking,
– DBT operates at a higher level of abstraction and is focused on simplifying effective data modelling and transformation.
– Spark operates at a lower level of abstraction and is focused on more sophisticated use cases with a wider scope.
Defining the scope
A data platform can be looked at as the orchestration of a set of data pipelines with additional components for serving the output of the pipelines.
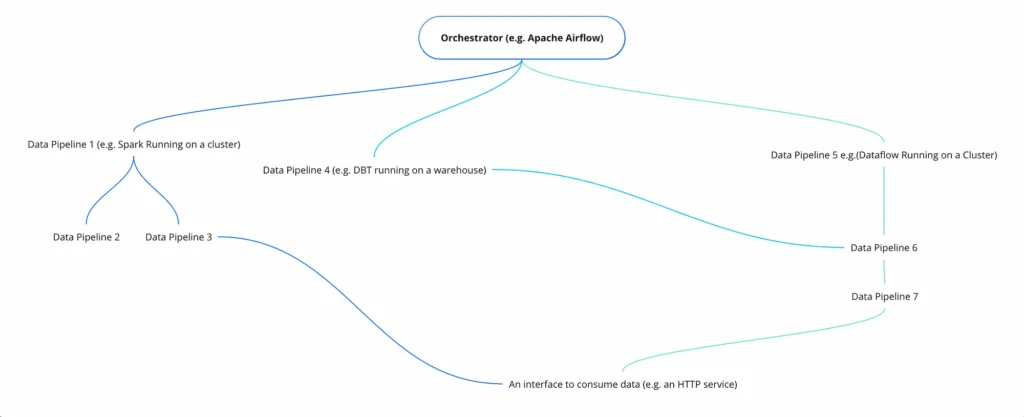
This is what a generic data pipeline looks like. The scope of this blog is limited to Transforms within a data pipeline (for the most part).

I’m working with a relatively small volume of data hence I have not performed direct cost and performance analysis for spark & DBT but there is a subsection that talks about cost and performance where I have listed some useful links and added my comments.
The focus of this post is more on less discussed topics like –
- In terms of development, testing and maintenance how do DBT and Spark compare?
- What type of use case is better suited towards the use of Spark compared to DBT and vice versa?
- What skills does a development team need to have to deliver production-grade models using these tools?
To demonstrate some common scenarios that come up while building a data platform, I’ll make use of the following openly available resources
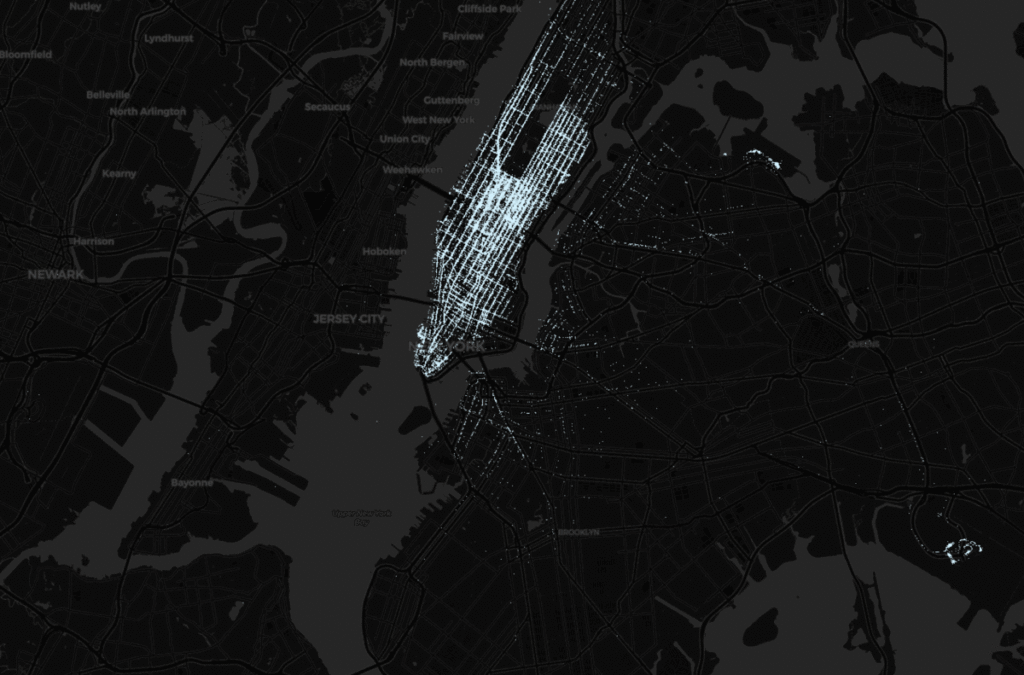
- NYC Taxi Trip Data: The New York City (NYC) Taxi & Limousine Commission (TLC) keeps data from all its cabs. The dataset consists of 3+ billion taxi and for-hire vehicle (Uber, Lyft, etc.) trips originating in New York City since 2009 and it’s freely available to download from its official website. I am only using data for June 2023 for demonstration purposes from this source.
- New York City Taxi Trip Duration: A playground Kaggle competition to build a model that predicts the total ride duration of taxi trips in New York City. The competition hosts a much smaller, cleaner version of the NYC Taxi Trip Data.
All the code referred to in this blog (and more) can be found in my Github repo NYC Taxi Trip Experiments.
It’s a monorepo containing
- Terraform code for GCS, GBQ & Dataproc resources
- PySpark code for all the use cases explained in the blog
- DBT code for all the use cases explained in the blog
- Code for creating visualizations using derived insights
Airport Insights: Example of a common analytics use case
What would you do if you were entrusted with figuring out the best time to do (digital) outdoor marketing at one of the airports in New York ?
A lot of factors will go into answering this question but one of the places to start could be to look at the trend of taxi pickups and drop-offs at JFK and LaGuardia airports because we have that data.
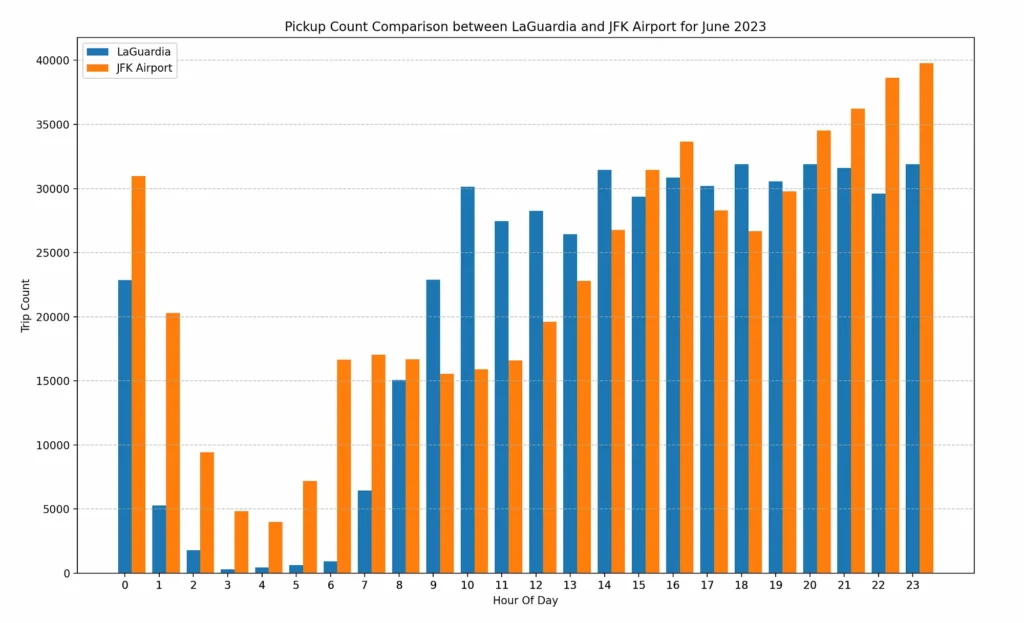
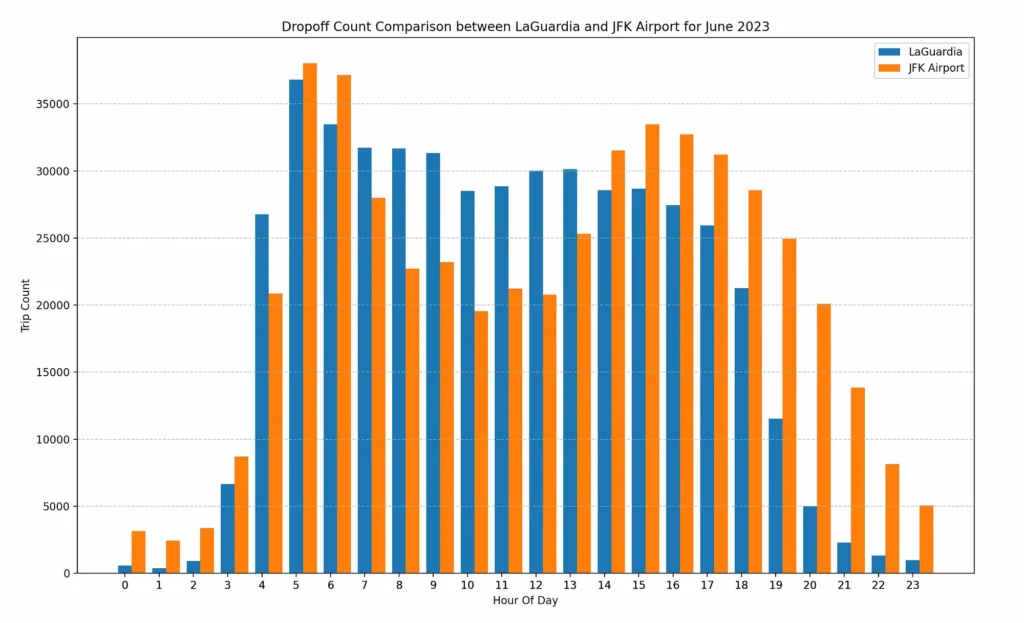
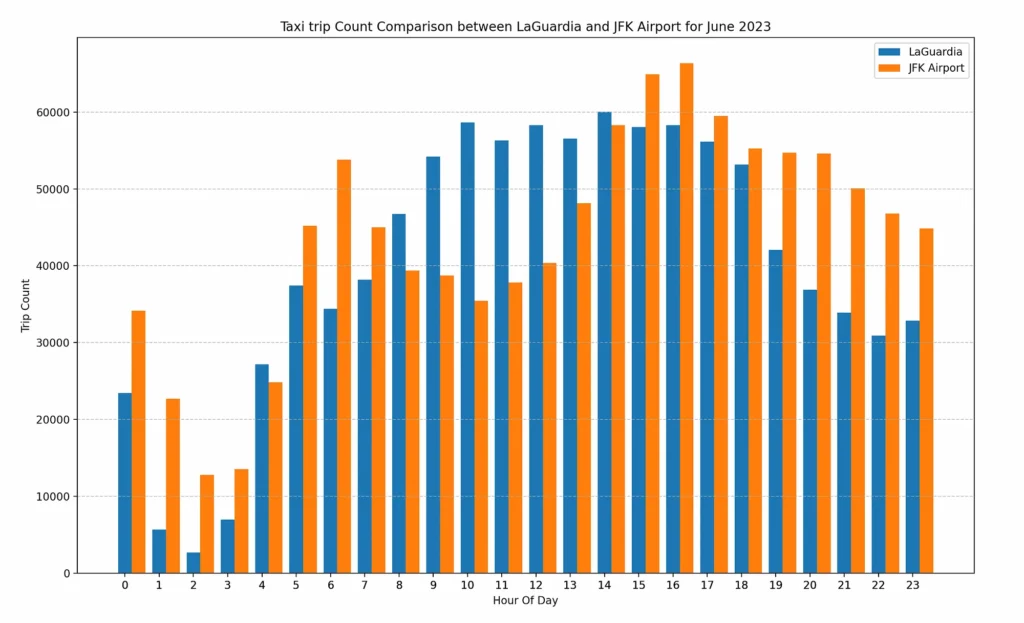
Insights: Charts indicate that,
- Between time window 9–13 hrs, LaGuardia airport has more taxi trips compared to JFK
- Between time window 20–23 hrs, JFK airport has more taxi trips compared to LaGuardia
Realistically speaking this is just a fraction of the information (if that) required to make the business decisions about actual outdoor advertisement at these airports, BUT, it’s certainly a real piece of insight hidden in the data and now we can compare how we can generate these insights using Spark vs DBT.
A spark job for insights on taxi pickups/dropoffs to airports
I have used PySpark for writing the transformations required.
Since I want to compare how different transform layer implementations will look like in production, it doesn’t make sense to just run the job locally so I have executed it on a single node dataproc cluster.
Note that all the data being used in the experiment has been uploaded to GCS using Terraform (refer to source). In an actual production pipeline, this task will be automated and will belong to the Extract part of the ETL pipeline.
The following gists are meant to give an understanding of the implementation of the job but for all code for this job refer to sources
— source code for PySpark job
— source code for dataproc resources in Terraform
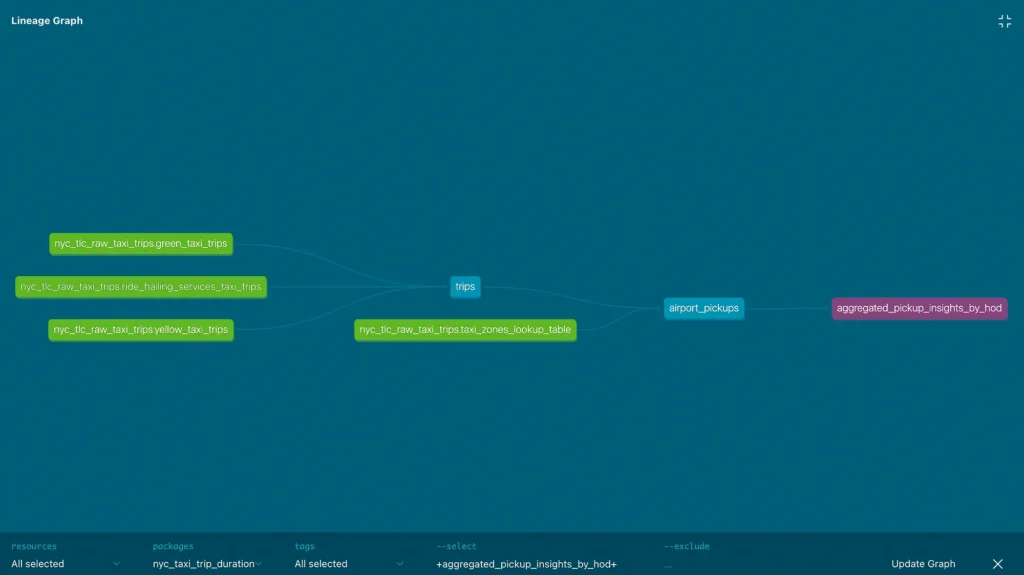
DBT model(s) for insights on taxi pickups/dropoffs to airports
I am using DBT with Google BigQuery for this experiment so all models are executed on GBQ by DBT.
In the blog, I have included a subset of models used for generating airport taxi trip insights using DBT. Check out all of them here.
Since DBT only operates on the Transform layer in ELT(Extract-Load-Transform) pipelines, I had to upload the source data into BigQuery tables using Terraform.
Comparison between Spark & DBT for developing an analytics use case
Spark
Implementing the transforms using Spark SQL is pretty straightforward as long as you understand Python (or Java/Scala depending on which Spark API you are using). It’s the rest of the setup that makes it a challenge.
For a data platform operating on a large scale in production, developers need to worry about questions like these –
- How many executors should I have?
- Is driver memory under/over-allocated?
- Is executor memory under/over-allocated?
- What is the optimal partition size?
- What should be the optimal cluster configuration (type of instances, number of instances, resources for instances)?
- Is my cluster performing efficiently?
- What happens when workload increases or reduces in subsequent runs?
- How do I monitor & profile the spark application on a cluster?
- How much is it going to cost me and what compromises can I make to optimize the costs?
- How should mechanisms to spawn cluster, ship code to cluster, start a run, monitor it for termination and destroy the cluster after the run finishes should look like?
Although developments like dynamic resource allocation and auto-scaling clusters have been of great help in offloading a lot of these issues, the development team still needs to be well aware of the intricacies that come with using spark in production.
Lastly, about testing – it might need some bit of figuring out to come up with testing strategies for Spark-based data pipelines but proper unit, integration and end-to-end testing can be (and has been) implemented for Spark applications.
DBT
Implementing transforms in DBT (once the setup is configured) is a cake. Production models can be developed by anyone who understands SQL, Data and Domain. DBT essentially democratizes the process of developing production models in data pipelines.
DBT has support for generating documentation which also includes lineage graphs which are useful in understanding the chronology between models.
When using DBT with BigQuery the concerns related to optimizations, scaling and infrastructure (which are very real when it comes to spark clusters) are practically non-existent because BigQuery is serverless.
If it is just SQL, what is it that DBT fixed which was broken before?
Developers with experience in building data platforms will tell you that using raw SQL to implement complex logic is a bad idea and it’s important to understand why (and how DBT fixed it)
- Bulky SQL queries are hard to maintain because they are unreadable.
Modularization: DBT promotes the modularization of code through the use of macros, models, and packages. By breaking down data transformations into reusable and composable components, DBT helps keep code organized and maintainable.
2. Logic implemented via SQL queries (especially ones written for cloud data warehouses) is hard to test.
Testing: DBT provided support for data and unit testing. Now I understand that it is not nearly as good as having a proper testing pyramid for your data pipeline (or application) but it does help cover a lot of ground.
3. SQL queries are hard to debug.
Modularization, Testing, Lineage and Dependency Graphs and Data Profiling in DBT make it easier to debug data pipelines. It can also be integrated with tools like re_data for improved data reliability through anomaly detection, test visualization and schema change tracking.
While testing in DBT is still not comparable to advanced debugging in application code, it is certainly very helpful.
4. SQL queries have code redundancy.
Macros: By defining logic in DBT macros, code can be made reusable.
Comments on the cost & performance of DBT + GBQ vs PySpark + Dataproc
Serverless data warehouses like BigQuery (Athena, Redshift, Synapse, Snowflake) usually have pricing models that are proportional to use i.e. higher the data stored & scanned or the frequency of queries or resources used for executing query higher the cost and vice versa so effectively it’s pay as per use.
I have not done independent cost & performance comparisons between BigQuery & Dataproc (yet) because I’m working with a small volume of data for demonstration purposes but here are some useful articles –
Apache Spark on DataProc vs Google BigQuery
A Billion Taxi Rides on Google’s BigQuery
BigQuery and Dataproc shine in independent big data platform comparison
Based on these articles (and my work experience), it seems like DBT with a capable serverless data warehouse like BigQuery (BigQuery on-demand-pricing is known to be cost-effective) or Athena will almost always be faster and cheaper compared to running spark on a cluster, let it be Dataproc or EMR or some other cluster but please note that there can’t be a generic answer for “Which solution is more cost-effective ?” on an actual project at web scale. It’ll depend on the scale of data, specifics of the computations performed and optimizations applied, spikes and analysis are required to make these decisions.
The comparison weighs in favour of DBT for the basic analytics use case explored so far.
Does it mean you should always choose DBT over Spark?
Short answer — NO
Taxi trip duration prediction: Example of developing a model for batch and real-time prediction
Imagine you run a ride-hailing service (Uber, Lyft etc), how would you develop a functionality to predict trip duration for taxi trips on your platform?
This use case can be broken down into two parts
- Developing a model that can predict the trip duration
- Using the trained model for real-time predictions
Now the 2nd part isn’t even meant to be done by DBT since DBT is designed to be used only in the transform layer in data pipelines so it shouldn’t be a surprise that it can’t be but lack of real-time stream processing is certainly a crucial limitation of DBT.
For this use case, I’ll use the default dataset provided by Kaggle in their challenge.
The data looks like this –

The solution —
I have done a minimal bit of feature engineering to derive columns more relevant to target column trip duration like hour_of_day, day_of_week, month, haversine distance between pickup & dropoff coordinates.
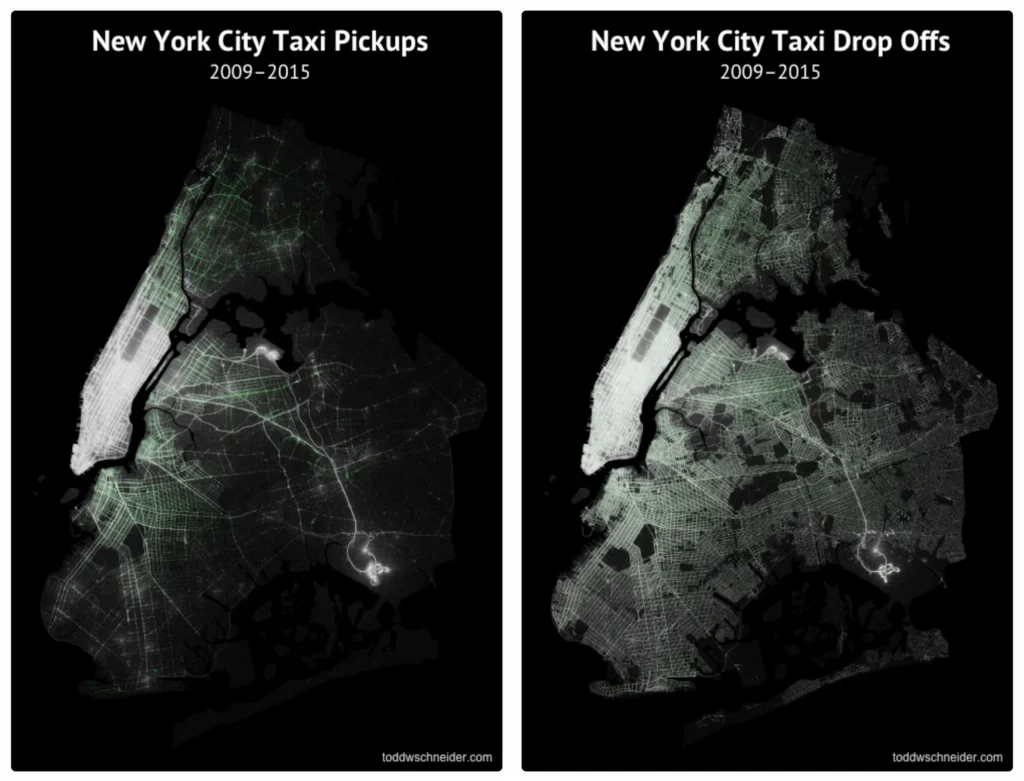
Looking at the visualization of pickups and drop-offs, it’s evident that pickups are concentrated in Manhattan and drop-offs are spread across other boroughs of the city hence doing some geospatial calculations to add borough or taxi_zone column is a sensible idea but for simplicity of the process I have not done this.
After adding relevant columns, some type of regression can be used to train a model and make predictions on taxi trip duration.
Spark
Similar to the prior use case, I’m uploading some snippets through gists so readers can get a rough idea about the implementation details of the solution.
Source code for trip duration prediction spark job.
I used the same cluster used for the previous use case to run this job.
DBT
Source for DBT models for trip duration prediction & macros.
Note that for macro defined to calculate haversine distance, the value of PI is used manually and a formula for calculating radians is implemented, the reason being Bigquery does not provide these as standard functions, unlike Python libraries.
Results
To my surprise, the solution created via Boosted Tree Regression in BigQuery ML ended up getting a better score on Kaggle compared to out-of-the-box Spark GBTRegressor but please note that these solutions have been developed with minimal feature engineering and with default models without overriding any model parameters.

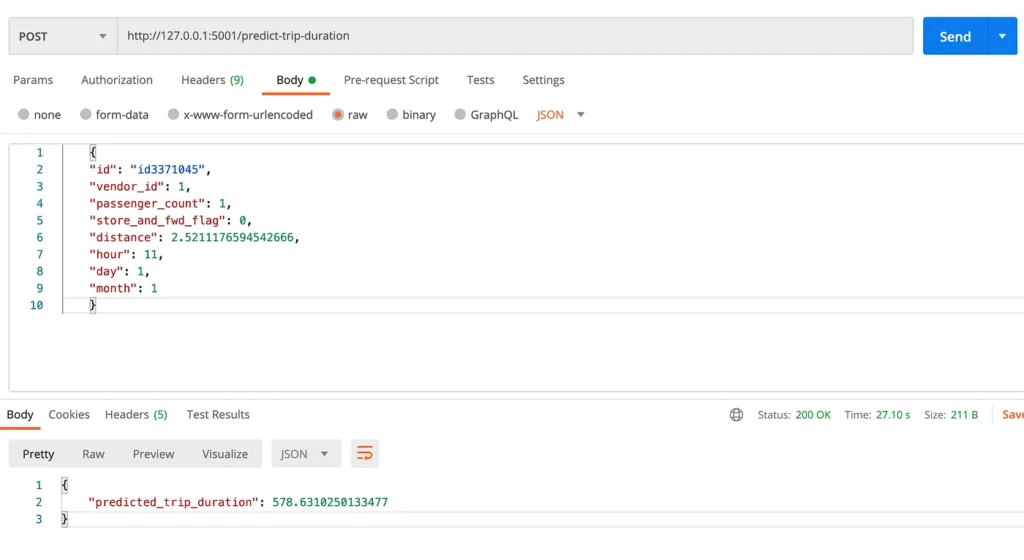
Now let’s quickly solve the 2nd part of the equation, by using the model for real-time prediction in an HTTP service. It’s super simple and this can only be done in Spark and not in DBT (for obvious reasons).
A locally running flask service that had an HTTP endpoint for real-time prediction of trip duration
Comparison between Spark & DBT for developing a data science use case
Developing a prediction model and using it in real-time is a more sophisticated use case in the development of a data platform compared to the one explored before for generating insights through some queries.
Spark has been adopted to develop big data processing and data science models in production for a long time now. It’s also used for machine learning to a lesser extent and does provide some support for distributed deep learning although it’s not been widely adopted for deep learning (as far as I know).
DBT on the other hand has been mostly adopted for building data transformation workflows and analytics in data warehouses.
For the super basic experiment I performed, both implementations turned out fairly straightforward with minimal feature engineering and default model parameters.
To implement an ML model using DBT I had to use the third-party package risteligt-dagblad but it worked out fine.
For this use case of developing a prediction model, purely based on the status quo, spark should be the preferred choice compared to DBT (given you have a scale of data that demands distributed processing) because it has been proven to work well for these types of use cases.
Another good reason to go with Spark over DBT is that multi-paradigm development is better supported in Spark than in DBT. When you are using DBT you are mostly relying on writing declarative code using SQL and for any imperative development you would have to rely on using macros and jinja templates which certainly isn’t my (and I can say with confidence most developers) favourite way to implement complex logic. When using Spark you have full might of the programming language(s) you are using (Java, Scala, Python) with you to implement any complex business logic (checkout Spark UDFs) in a readable efficient and well-tested manner using imperative code while still using Spark SQL and other declarative libraries Spark provides.
DBT might still work but not all DBT backends have support for sophisticated use cases such as a prediction model. The ones who do (e.g BigQuery ML, Redshift ML, Snowflake ML, did you know there is also a PostgresML) are still new, might not have the full range of machine learning models & feature engineering tools required by your use case and haven’t yet seen wide-scale adoption, also using the AI/ML capabilities of cloud data warehouses might not always be straight forward in DBT. Another very real issue that might come while going via the DBT route is vendor locking but that is true to a lesser extent even for Spark because you’ll be using some cloud-based big data platform like EMR or Dataproc for running Spark clusters.
There is support in DBT for integration with Spark, I haven’t explored this area but thought it’s worth mentioning.
Can Spark solve all DS/ML use cases? Answer — NO
I’ll just mention the limitations of Spark that I came across while working with a vector prediction problem.
- Compute optimized Dimensionality Reduction
If you do not have enough compute, dimensionality reduction on large data sets is painful in Spark because Spark MLlib does not have support for methods such as Incremental PCA or Truncated SVD which are supported in sk-learn (but sk-learn isn’t distributed so either way, you have a problem if you are working with big data).
2. Multi-target regression (a subset of Multivariate regression, different from Multiple regression).
Multi-target or multi-output regression is where the target/output you want to predict isn’t a single numeric value (e.g. price of a house) representing a real-world metric instead it’s a vector representing a set of metrics (e.g. likelihood for all grades or stages of a cancerous tumour).
Multi-target regression isn’t directly supported in Spark, you would have to build an ML Pipeline in Spark treating the target vector as a set of independent numeric target variables and do predictions for each variable separately which might not have comparable accuracy to an actual multi-target/output model, also it’ll be extremely compute intensive because you are essentially repeating the prediction computation for each value in the target vector. While sk-learn does have regression models that accept the target as a vector — like I mentioned before, the library not being distributed still poses challenges working with big data.
Push of tech giants towards expanding the use of serverless data warehouses beyond conventional OLAP
Tech companies (especially the big ones) with cloud-based warehouse services (Google, Snowflake, Amazon, Microsoft and even Yandex) are pushing for going beyond using the warehouse for conventional OLAP and using it to build more sophisticated use cases including data science, machine learning, deep learning and if you can believe it you can also train your beloved LLM on BigQuery using SQL.
Google is going big on BigQuery
BigQuery Breaking News — Generative AI
SQL-only LLM for text generation using Vertex AI model in BigQuery
So the landscape of tech for building modern data platforms is seeing change and evolution. As a consultant, the idea of using DBT with BigQuery to build sophisticated use cases and deploying them to production in days that would otherwise take weeks by conventional means like a series of spark jobs on clusters is tempting, to say the least, but I haven’t yet gotten the opportunity to try this out in an actual project at scale yet so I’ll hold my judgement on that for now.
Thank you for reading!

