
Consistency in Distributed Systems
In today’s world, databases are the backbone of information flow, much like roads guiding traffic 🚗. Just as roads differ in structure, databases rely on varying consistency models to manage data. In distributed systems, where data is replicated across multiple nodes or data centers, ensuring that all users see the same data simultaneously can be challenging, especially during high traffic or network failures 🚦. These conditions can cause nodes to temporarily hold different data copies, making synchronization across the system complex and tricky. ⚙️
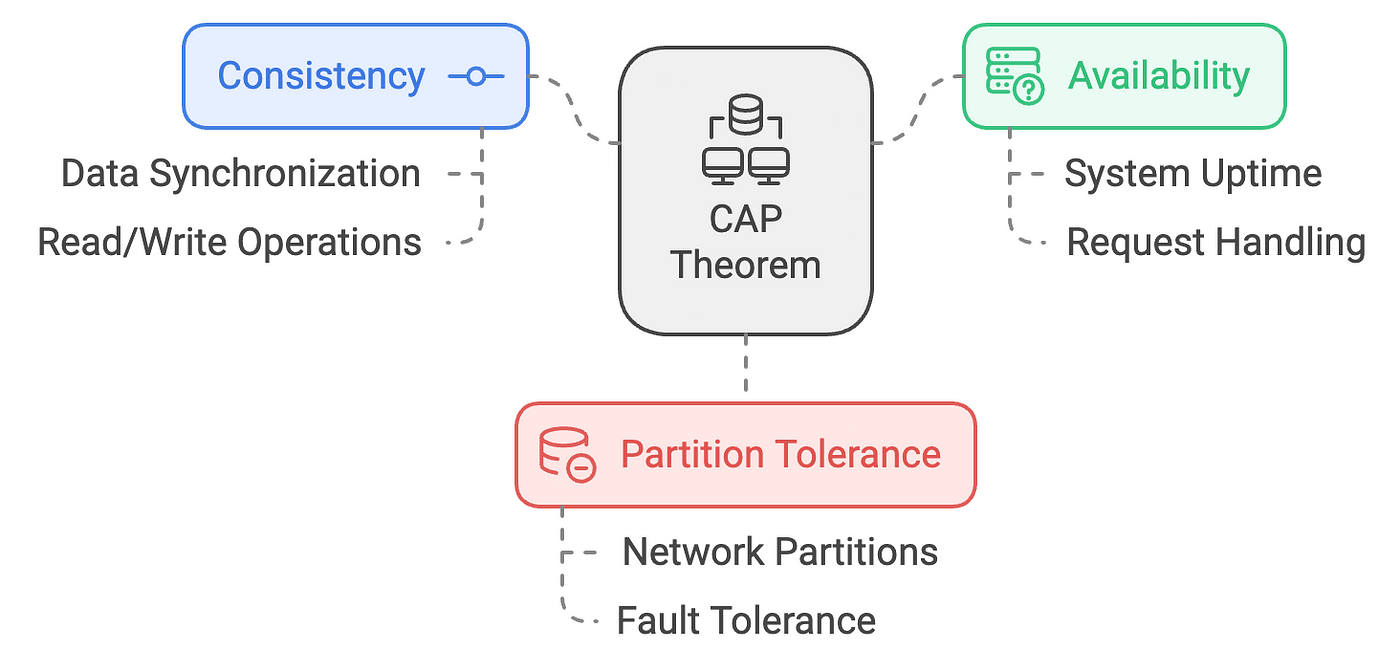
This is where Cassandra’s tunable consistency comes into play, offering flexibility to manage consistency based on specific operational needs, balancing the three pillars of the CAP theorem (Consistency, Availability, and Partition tolerance).
The CAP theorem states that in a distributed system, you can only guarantee two out of three properties: Consistency (all nodes see the same data at the same time), Availability (every request receives a response, even if some nodes are down), and Partition Tolerance (the system continues to function despite communication breaks between nodes). It highlights the trade-offs inherent in distributed databases.
The Problem with Traditional Consistency Models
Think of a restaurant during peak hours 🍽️. A chef focused on strong consistency insists every dish must be perfect before serving, ensuring quality but slowing service. Meanwhile, another chef using eventual consistency sends dishes as soon as they’re ready, even if they vary momentarily — this speeds up service but raises the risk of quality dips 🍲⚡.
Traditional databases work similarly: strong consistency prioritizes accuracy but slows down under high traffic, while eventual consistency boosts speed at the cost of temporary data inconsistencies. 🚦
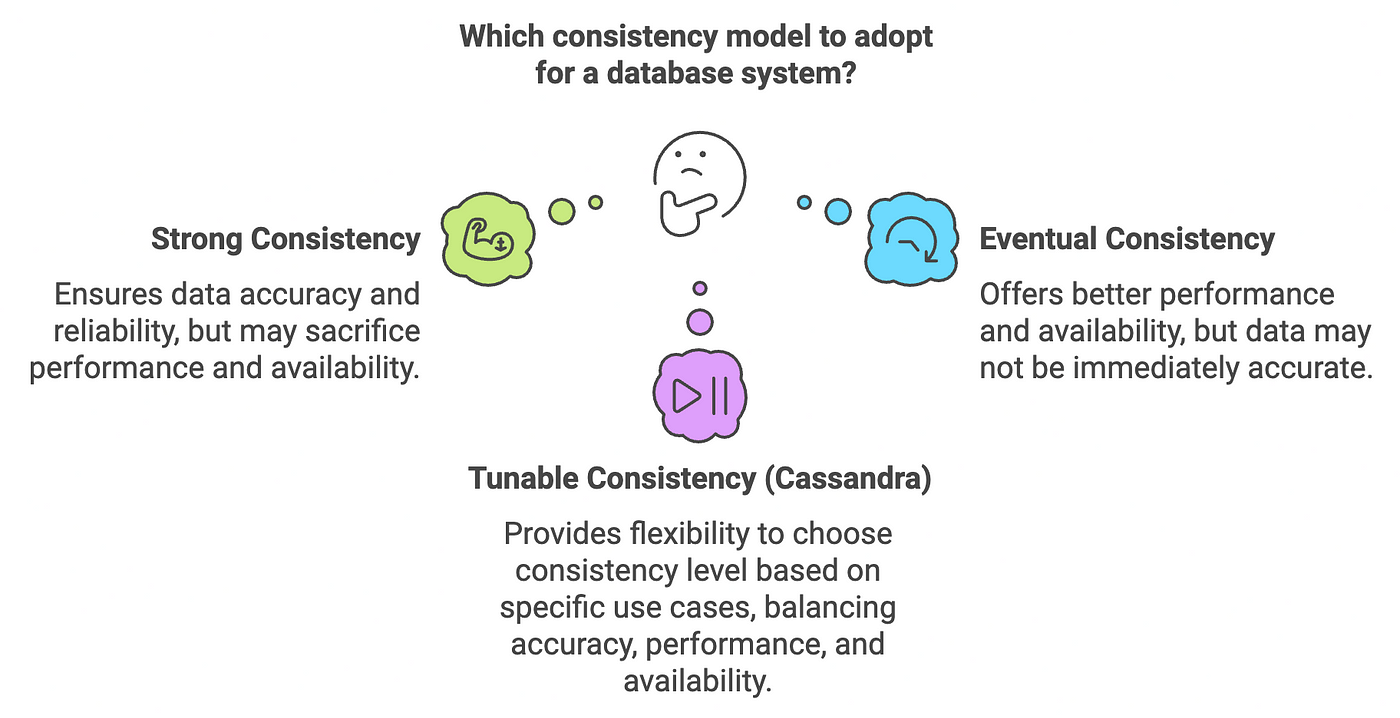
Both models are sometimes ideal. Some applications require immediate consistency, while others can tolerate a brief delay for faster performance. Cassandra introduces tunable consistency, allowing you to adjust consistency levels based on specific application needs. 🎛️
Cassandra’s Tunable Consistency: The Flexibility of Cassandra
Cassandra’s tunable consistency allows users to customize the balance between ⚡ performance and ✅ accuracy for both write and read operations. You can control how many replica nodes confirm operations before they are considered successful. Let’s dive deep to see how Cassandra ensures 🔄 Read and ✍️ Write consistency!
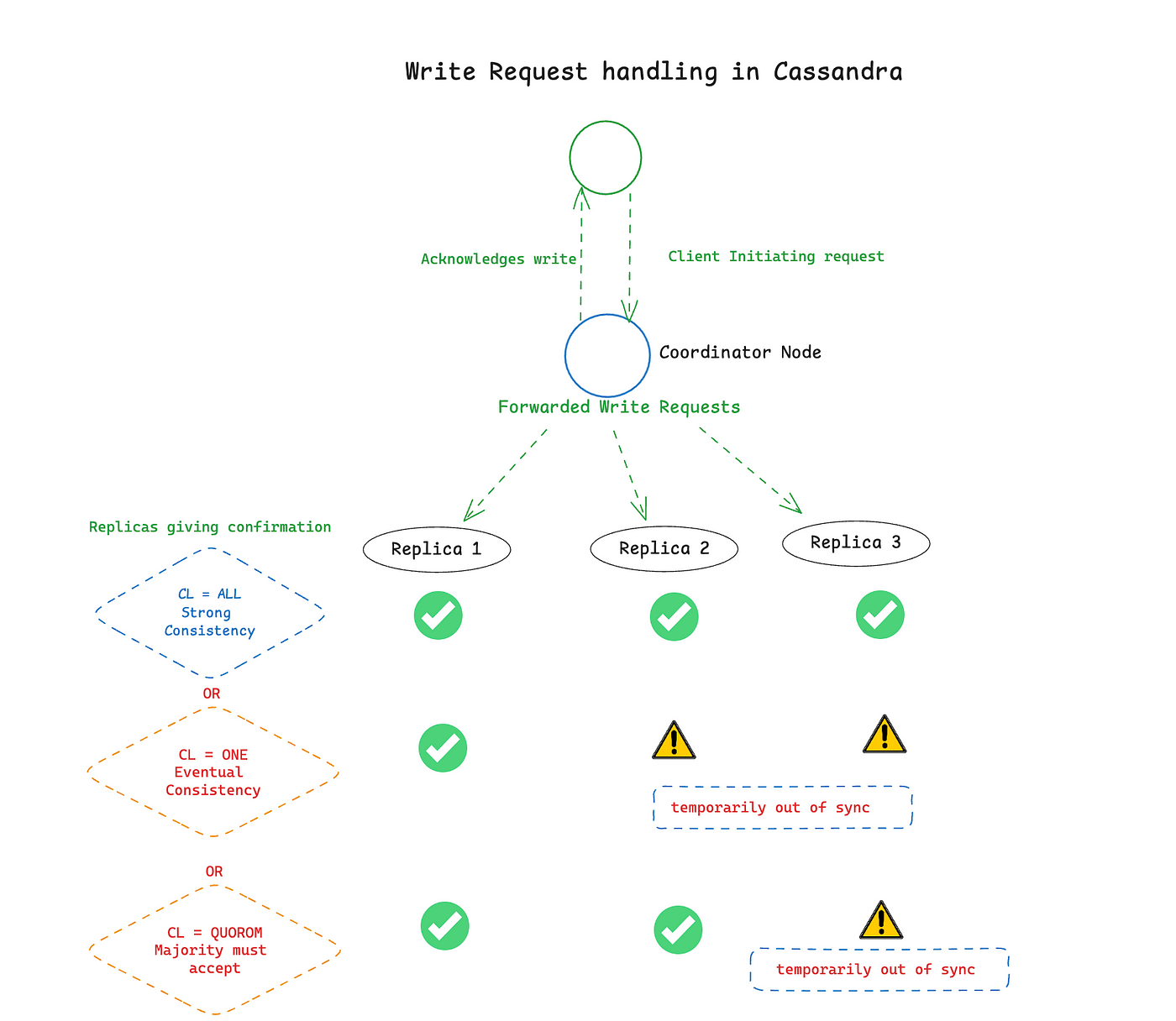
Write Consistency in Cassandra 📝
When a write operation is performed, Cassandra manages consistency across replicas either instantly or eventually. Here’s a breakdown of the process:
1️⃣ The client sends a write request to the coordinator node.
2️⃣ The coordinator forwards this request to the necessary replica nodes.
3️⃣ The number of replicas that must acknowledge the write is determined by the write
Consistency Level (CL) you select.
4️⃣ Once the required replicas respond, the coordinator returns a confirmation to the client.
🔍 Examples:
Write CL = ALL: All replicas must confirm the write, ensuring maximum consistency but potentially slowing performance (Immediate Consistency).
Write CL = ONE: Only one replica needs to be confirmed, offering faster performance but risking temporary data inconsistencies across replicas (Eventual Consistency).
Write CL = QUORUM: A majority of replicas must acknowledge the write, balancing consistency and speed, often used for critical operations that need higher reliability.
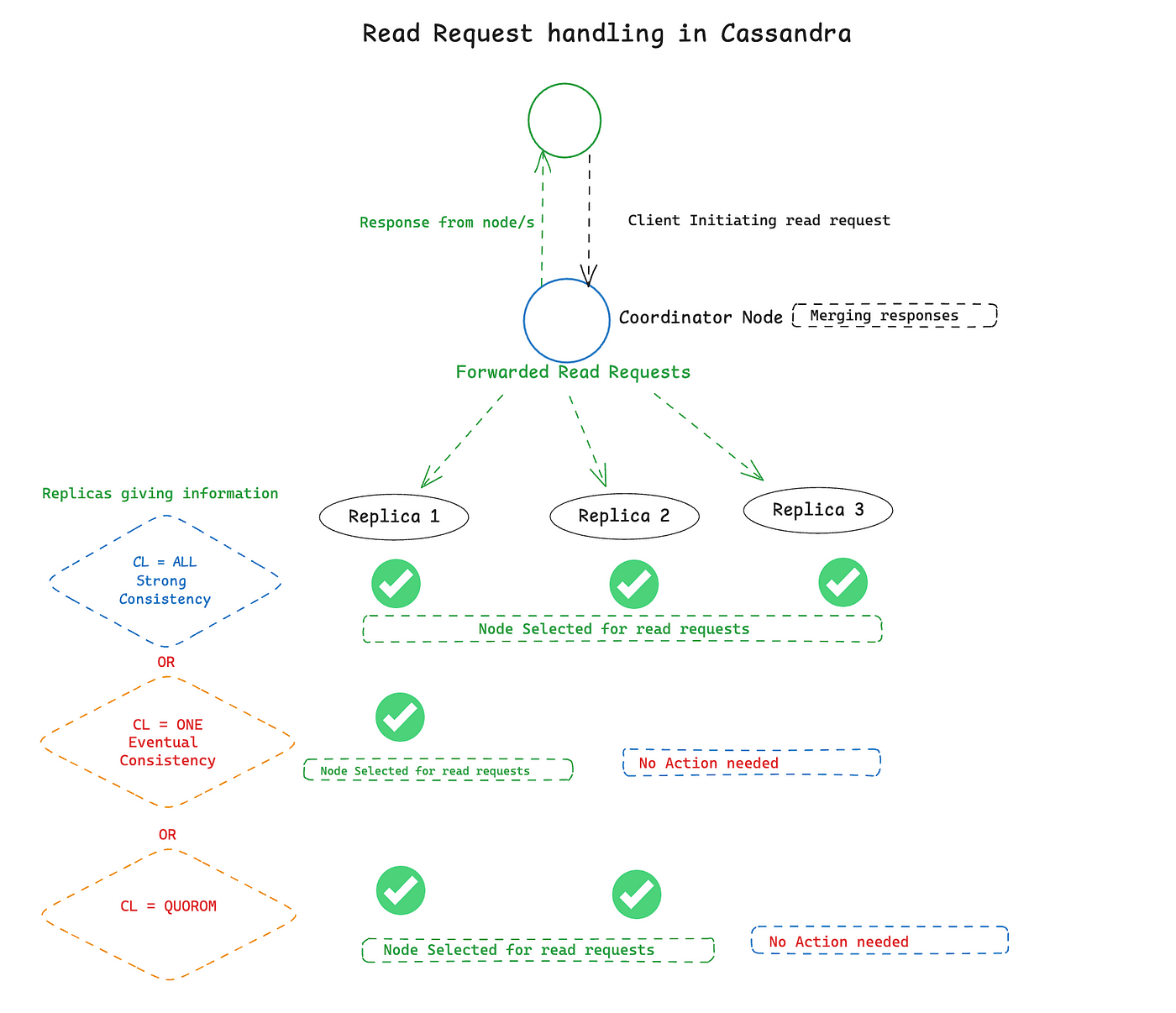
Read Consistency in Cassandra 📖
Cassandra’s read consistency dictates how many replicas must agree on the data before a response is returned to the client:
The client sends a read request to the coordinator node.
The coordinator retrieves data from a set of replicas based on the configured read Consistency Level (CL).
The coordinator merges responses and returns the data to the client.
For instance:
Read CL = ONE: Reads from a single replica, ensuring fast access but risking the possibility of stale data.
Read CL = ALL: Reads from all replicas, ensuring that the most up-to-date data is returned, but possibly at the cost of speed.
Read CL = QUORUM: A balance where the majority of replicas must agree on the data, combining both speed and accuracy.
Consistency Models in Cassandra
1️⃣ R + W > N: This ensures strong consistency.
(At least one replica in a read will have the most recent write)
2️⃣ W + R ≤ N: This reflects eventual consistency.
(Not all replicas need to acknowledge the read/write, allowing for temporary inconsistencies)
3️⃣ R + W ≥ N/2 + 1: This represents quorum consistency.
(A majority of replicas participate, balancing consistency and availability)
R: The number of replicas that must agree during a read (read consistency level).
W: The number of replicas that must acknowledge the write (write consistency level).
N: Total number of replicas (how many nodes hold copies of the data).
Immediate vs. Eventual Consistency ⚖️
Cassandra gives you the flexibility to choose between:
🔗 Immediate Consistency: Ensures that all replicas have the same data immediately after a write by setting a higher consistency level like ALL. This guarantees accuracy but might slow down the system.
⏳ Eventual Consistency: Allows temporary differences in data across replicas, ensuring they eventually converge. Achieved with lower CLs like ONE, it boosts performance but risks short-lived inconsistencies. Adjust based on your app’s needs!
Tunable Consistency Levels in Cassandra 🎛️
Cassandra’s tunable consistency model provides flexibility with several options:
➡️ ONE: The fastest and most available; only one node acknowledges the operation. Ideal for scenarios prioritizing speed over strict accuracy.
➡️ QUORUM: A majority of nodes must agree, balancing speed and accuracy. This level is often used in applications where reliability is crucial but speed remains important.
➡️ ALL: All replicas must confirm the operation, ensuring the highest level of consistency but potentially sacrificing availability and speed.
➡️ LOCAL_ONE: Guarantees that one replica in the local data center responds, particularly useful in multi-region setups where local performance is key.
➡️ EACH_QUORUM: A quorum from each data center must respond, providing resilience and consistency in multi-data-center deployments.
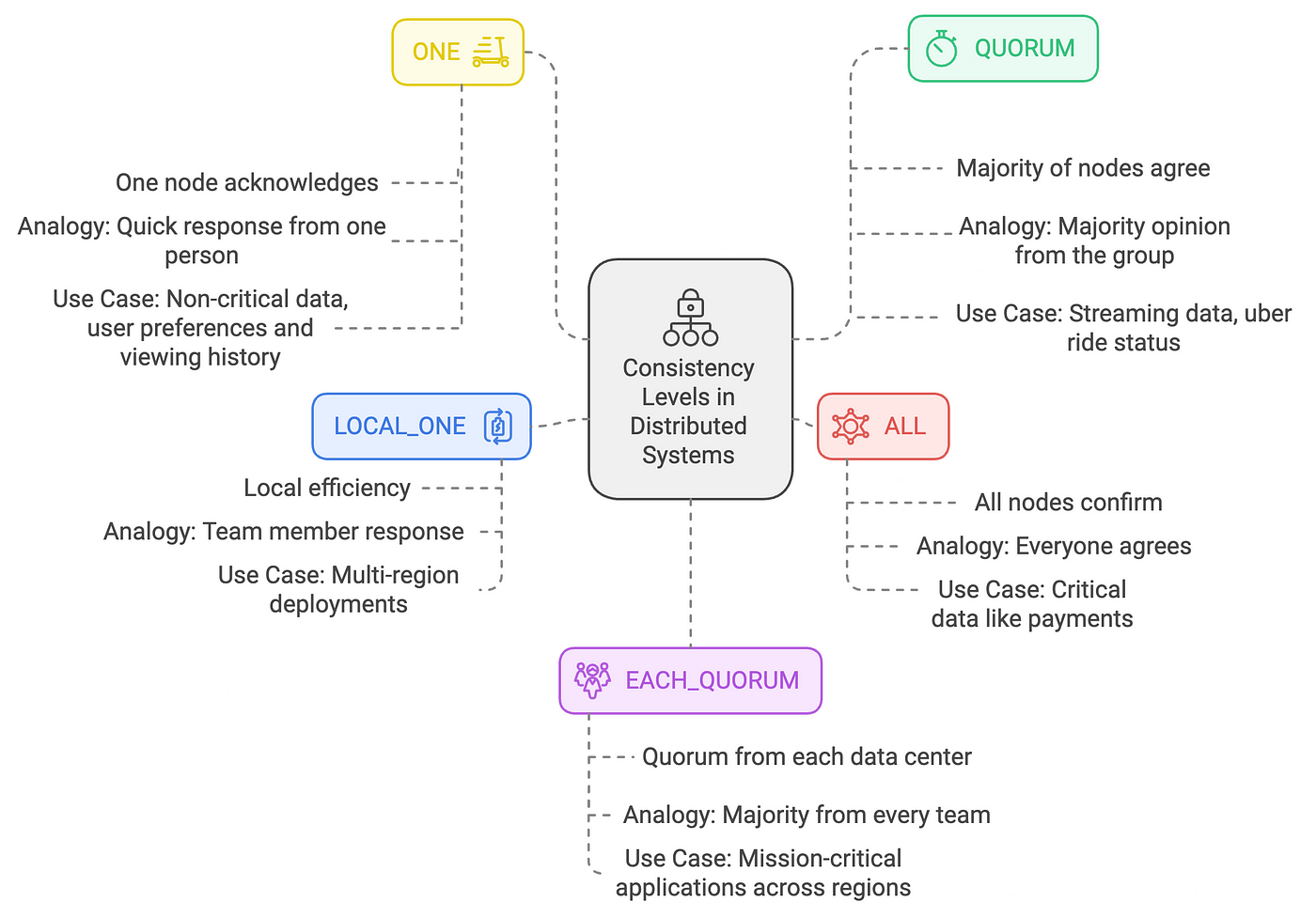
Types of Tunable Consistencies in Cassandra
Real-World Use Cases
Imagine you’re running a global streaming platform like Netflix. You may prioritize fast writes for user activity logs with Write CL = ONE, but ensure a higher consistency level, like QUORUM, for critical data such as user subscriptions. Similarly, Uber might opt for fast, real-time GPS updates with Read CL = ONE, but use Write CL = QUORUM for financial transactions.
Conclusion: The Power of Cassandra’s Flexibility
🚀 Cassandra’s tunable consistency model offers the flexibility to balance performance, reliability, and scalability based on your specific needs. 🌍 Companies like Netflix, Uber, and Instagram rely on this adaptability to manage massive data loads while maintaining a smooth user experience. 🎯 Whether you need immediate accuracy or can tolerate eventual consistency for faster performance, Cassandra lets you adjust the consistency level to fit your requirements, ensuring optimal performance for any application in a dynamic digital environment. 💡⚖️

