

Databases like PostgreSQL and MySQL provide various locking mechanisms to control concurrency and to avoid data corruption. We looked at different locks in a previous blog and in that I briefly covered advisory locks.
In this blog let’s take a deep dive into it. We will implement the locks on the database and see how they work. I have also provided the code implementation for it in Java so that you can use it in your applications.
What are Advisory locks and why are they special?
Advisory locks are locks provided by the database that you can control via your application. It’s a utility that helps you manage concurrency when you want to keep your application stateless.
There are different locks that the database provides out of the box and most of them are managed by the database until you specify something specific. PostgreSQL provides row level, table level and page level locks.
But these are locks used by the DB and the application doesn’t have any control over them. That’s where advisory locks come in.
Why do you need it?
Before diving into the nuances of advisory locks, let me tell you the problem that it’s trying to solve and the use cases where it’s used.
Imagine a scenario where you have a distributed system talking to a central database. You are supposed to control the access to the data for all the systems or nodes that are talking to the database and no two nodes are supposed to alter the data at the same time.
In such a scenario you can control the flow of program by having an advisory lock. If a node is able to acquire the lock then you let the node have the access to the data. And the rest of the nodes either wait for the node to finish or report back to the application that the lock wasn’t acquired.
Note: Remember that, here we are not locking the data itself. If you try to access the data from elsewhere. Only the piece of code that you have explicitly enclosed in your application for advisory locks gets affected by the lock.
Imagine it this way. The advisory lock is a gateway for certain piece of code in your application while the other pieces of code in your application is free to do whatever it wants to do with the data.
This scenario can arise when you have to send a notification or a report to someone. The data for that resides in a central database. You might have designed the system to run a cron job and send a report or notification everyday. But your application logic resides in multiple nodes and if they all execute at the same time then multiple reports/notifications will be sent out.
To avoid this you can have all the nodes try to acquire an advisory lock and if one of them is able to do that, then execute the logic to send the notification/report.
Keep in mind that these locks are still managed by the database. If you are using PostgreSQL and you try to list all the locks that are acquired on it then you will be able to view them (we will see this in some time).
Other use cases for advisory locks back be when you want to run a background process that should be executed by only one worker or a node. Advisory locks can be used to make sure you are not wasting your compute power, executing the process more than once.
Types of advisory locks in Postgres
I have been using PostgreSQL since forever. So I will focus on PostgreSQL here.
You can acquire an advisory lock on a session level or a transaction level. Just like the other locks, if the lock is acquired on a transaction level, the lock is released when the transaction is complete. Similarly, a session level lock is released when the session ends or when you manually release it.
You can acquire an advisory lock using either a blocking or a non-blocking function. In the blocking function, the process trying to acquire the lock will wait till the lock is acquired while in the non-blocking function, the process will immediately return with a boolean value stating if the lock is acquired or not.
In the use case mentioned above of sending a report or notification where only one node should execute it, a non-blocking function seems to fit well. When each of the nodes try to access the lock at the same time, only one node is able to acquire the lock and the rest of them returns a false value indicating that they were not able to acquire it. This is in contrast to the blocking function where the function would have waited to acquire the lock.
A blocking function is useful in scenarios where you need to make sure that a record is getting updated by only a single thread or a node at a time. So it will wait for one of the threads or nodes to release the lock and update the records after the previous thread is done updating them, maintaining data consistency.
Let’s try this out in PostgreSQL. Connect to your PostgreSQL database using any client. I am going to use my terminal to do this.
Let’s try to acquire a session level advisory lock. For this you will have to use the pg_try_advisory_lock() function of Postgres and pass any 64bit number as an argument.
SELECT pg_try_advisory_lock(100);
It will return true and if you try to query the advisory locks on the database you will get something like this
SELECT mode, classid, objid FROM pg_locks WHERE locktype = 'advisory';

Now open a new session in the terminal and connect to the database again. Now try to run the above command to acquire a lock on the same integer (100).
You will get a false value in return, indicating that you were not able to acquire the lock. Any new session will not be able to acquire this lock until the old one releases it. The new session can however acquire a lock on another integer, let’s say 101. So if there are multiple processes using the advisory lock, you can configure it to use different integer values to acquire locks.
The command we used above to acquire the lock (pg_try_advisory_lock) is a non-blocking function, which means it will immediately return with a boolean indicating if it was able to acquire the lock or not.
Let’s try acquiring the same lock (integer 100) on the new shell using the blocking function shown below.
SELECT pg_advisory_lock(100);You will see something similar to the image below, where there’s no output or new prompt.
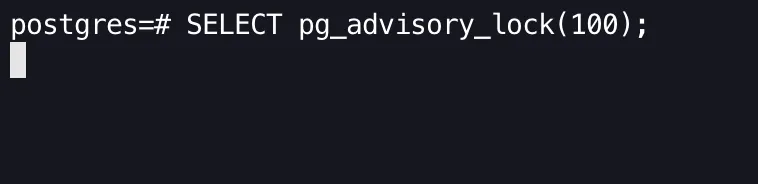
Now let’s release the lock we acquired in the old shell and see how it changes the output in the new shell.
SELECT pg_advisory_unlock(100);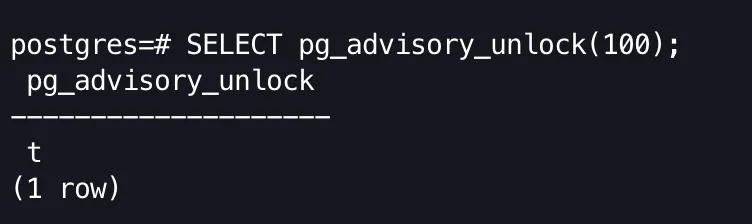
Note: Make sure you have removed all the locks by first querying for all the advisory locks and unlocking them.
Java implementation for Postgres
The following code snippet works for a Springboot application. Please do your due diligence and test your application properly before deploying it to production with the following code.
Here we have created a Manager to manage the lock along with a method that will return a boolean of whether it was able to acquire the lock. The method takes an integer as argument. This integer will be used to acquire the lock. The calling function can pass a fixed integer every time it’s called. We are using an EntityManager instance to create and execute a native query.
Since I want to limit the query for every transaction, I am using the transaction level function i.e. pg_try_advisory_xact_lock()
public class AdvisoryLockManager {
private final EntityManager entityManager;
@Autowired
public AdvisoryLockManager(EntityManager entityManager) {
this.entityManager = entityManager;
}
public boolean acquireLock(int lockIdentifier) {
String pgLockQuery = String.format("SELECT pg_try_advisory_xact_lock(%s)", String.valueOf(lockIdentifier));
Query pgLockQueryResult = entityManager.createNativeQuery(pgLockQuery);
return (Boolean) pgLockQueryResult.getSingleResult();
}
}Wrapping up
While the concept might have been a bit confusing in the beginning, I hope by now you understand how advisory locks work. We have learnt about its use cases and also understood how to use them.
The above examples were for PostgreSQL, MySQL has its own version of advisory locks. You can check them out in the official MySQL documentation.

