
The trick is to make everything simple !
Knowledge graphs are becoming increasingly popular with different applications in AI, due to their ability to render a cognitive representation of unstructured data, that readily allows for reasoning and information extraction. Knowledge graph (KG) is a directed labelled graph. In case of sentences from text datasets, the nodes of the graph are constituted by subjects or objects, and edges are constituted by verbs. Equivalently, a KG can be detailed as a set of factual triples where each triple assumes the form of (subject, verb, object) corresponding to each sentence under consideration. Automatic extraction of these triples from sentences follows a sequence of natural language processing (NLP) steps.
The accuracy of KGs generated from text becomes crucial in certain applications, like representation of research articles, criminal investigation reports and insurance reports. Ensuring accuracy of KGs generated is a challenging task particularly, when the text under consideration has a complex structure. We may have to address multiple compound sentences with progressing relationships. Extraction of subject, verb and object from compound sentences to create the SVO triples is not a simple task.
Generally, we may restrict the KG generation to simple sentences with exactly two named entities in them, which will be an acceptable strategy only if we can tolerate the associated information loss. In case of compound sentences with multiple verbs and several entities surrounding them, it requires specific sentence-level preprocessing to restructure and address progressive relations in complex text. In this article, a simple process pipeline that is explicitly catered towards KG generation from text data of complex nature is explained.
KG generation pipeline
The overview of the process pipeline for KG creation from complex text is shown in Figure. 1. The general description of the pipeline is as follows: preprocessing of text data aims at text cleansing with the intent to remove unwanted characters, punctuations, tagged blocks of text, etc. Header and footer text, if exist and unwanted, will be removed as well. Removal of digits and stop words, which is usually a part of text cleansing, is performed later in the pipeline as this may affect the quality of dependency parsing required for triples extraction. Sentence segmentation generally uses periods to identify individual sentences. The creation of triples, aka subject-verb-object (SVO) triples, for KGs relies on dependency parsing tags. Finally, refinement of resultant KG aims at cleansing of the set of triples, in order to remove stopwords, digits, triples with subject equals objects, etc.
These processes are generally part of a base pipeline for KG generation, and most of the NLP operations required for these processes can be implemented using pertained resources in packages like spaCy. A detailed introduction to KGs can be found here and implementation of a base pipeline for KG creation can be found here.

The processes added to the base pipeline, that specifically addresses compound sentences and their progressing relations are the coreference resolution and compound sentence splitting. The former aims at identifying multiple mentions of named entities by their pronouns and replacing all these mentions with the original named entity, where the latter intends to split compound sentences to simple sentences such that there exist only one SVO triple in each of the simpler sentence.
Coreference resolution
Consider a fragment of text data from the Clinton emails dataset as , “Akiva Eldar is the chief political columnist and an editorial writer for Haaretz. His columns also appear regularly in the Ha’aretz-Herald Tribune edition. In May 2006, The Financial Times selected him among the most prominent and influential commentators in the world, and his comments inspire callers from across the political spectrum”. Here, the name ‘Akiva Eldar’ is a named entity with label ‘PERSON’ which is mentioned multiple times.
The coreference resolution is expected to replace all the pronouns of this named entity by the entity itself. The coreference resolution can be realised using packages ‘neuralcoref’, which works with spaCy 2 and ‘coreferee’ to work with spaCy 3. An example of coreference resolution using coreferee and spaCy is given below.
After the coreference resolution, the text becomes:
“Akiva Eldar is the chief political columnist and an editorial writer for Haaretz . Eldar columns also appear regularly in the Ha’aretz-Herald Tribune edition . In May 2006 , The Financial Times selected Eldar among the most prominent and influential commentators in the world, and Eldar comments inspire callers from across the political spectrum”.
Compound sentence splitting
The coreference resolved text, with compound sentences, is split into a set of simple sentences. For this task, the verb ancestry tree of a sentence is utilised. The spaCy package provides the verb ancestry tree for identifying the hierarchy of verbs, where the root verb will be identified as the ancestor and all other verbs will be listed out as children. For each child, the ancestor will either be the root verb or the another preceding verb. Then, simple sentences are constructed for each verb, by grouping the subjects/objects around them based on their proximity in a sentence. An example of the implementation of compound sentence splitting is given below.
After compound sentence splitting, the last sentence in the text-example, mentioned in the section above, becomes a set of 2 sentences as : [“In May 2006 , The Financial Times selected Eldar among the most prominent and influential commentators in the world” , “Eldar comments inspire callers from across the political spectrum”]. After SVO triples extraction from this set of simple sentences, cleansing and refinement, the following set of triples is obtained:
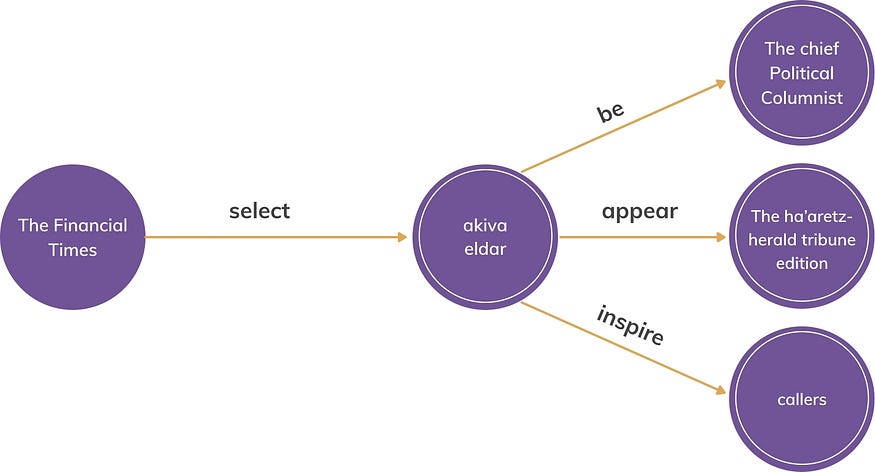
[ (akiva eldar, be, the chief political columnist),(eldar columns, appear, the ha’aretz — herald tribune edition), (the financial times, select, eldar), (eldar comments, inspire, callers) ].
The resultant KG representation is shown in the Figure. 2, after tying entities, merging nodes and refinement. This KG faithfully captures the underlying meaning from the sentences under consideration in a condensed manner.
Comparison with base-pipeline for KG creation
The two specific processes added to address complex text in the KG creation pipeline are coreference resolution and compound sentence splitting. If we were to use a base-pipeline for KG creation from complex text, without these specific processes, we would have obtained the set of triples for KG as:
[(akiva eldar, is, editorial haaretz), (columns, appear, regularly), (prominent comments, selected, political spectrum)]
The base-pipeline for KG creation is affected by confusions between nouns and their pronouns. Also, the compound sentences clearly create inaccuracies in the base-pipeline’s KG outcomes, as it tries to associate verbs with subjects and objects in a compound sentence with multiple verbs. On the other hand, the improvised pipeline successfully addresses these complexities, resulting in more accurate KG representation of complex sentences.
Conclusion
It is not a simple task to extract SVO triples from compound sentences, and hence, KG generation may be inaccurate if we do not include specific processes in the process pipeline for creating KGs. In this article, two such specific processes to address the challenges imposed by compound sentences on KG generation are explained. The processes included are coreference resolution and compound sentence splitting, creating an improvised process pipeline for KG generation from complex text. The tech stack for the process pipeline primarily includes spaCy and Coreferee packages in Python.The resultant KG created from complex text provided a faithful representation of text capturing the meaning well without significant loss of information.
I would like to thank Ravindra, Venkatesh and Trishna for their time and effort in reviewing this article. And, thank you Niki for the gorgeous art !

