
Today, storing a person’s KYC information, credit card/debit card information, or other similar sensitive details to charge for services availed on a platform is commonplace. This entails storing & dealing with Personally Identifiable Information (PII) and sensitive financial information. Hacking of such systems can expose businesses to the following risks:
- Customer identity theft results in financial losses and damage to an individual’s credit score.
- Loss of trust and reputation of the enterprise in event of data breach and exposure.
- Legal liability to the enterprise managing the PII Data amounting to hefty fines and penalties.
- Accidental or intentional updates of PII data points by developers with elevated system access result in data inaccuracy.
It is extremely important to build controls to safeguard sensitive customer data.
We have been working with a customer in the FinTech space at Sahaj and building their lending platform for commercial vehicles. As part of the business process automation, we collected their users’ Personally Identifiable Information (PII) containing data points like mobile numbers, email addresses, PAN numbers, AADHAAR, and Cibil Details. As per compliance requirements and reasons mentioned already, PII Data protection was an important business objective.
PII data protection becomes even more important in the Indian context with the Data Protection bill planned to be tabled in Parliament in 2023–24.
This two-part blog covers different options available to protect sensitive PII data and insights that would help weigh them before making a decision in a certain use case. Further, it delves deep into achieving Database Level encryption with Postgres, SpringBoot, and Hibernate Tech stack — illustrated with a working example.
To achieve PII data protection, multiple considerations and approaches can be taken:
- Tokenization vs Encryption
- For an encryption-based approach:
- Client-side encryption (application-level encryption) vs database level encryption
- Symmetric encryption vs asymmetric encryption
- Tokenization
- The process of transforming a piece of data into a random string of characters is called a token.
- Have no direct meaningful value to the original data.
- Tokens serve as a reference to the original data but cannot be used to derive that data.
- Tokenization is a pseudonymization technique (making sensitive data points less identifiable by replacing them with a token or a pseudonym).
- Does not leverage any mathematical function/algorithm to derive the token from sensitive data.
- Uses a database called token vault to store the token and the sensitive data against which the token was generated.
- A simple example of tokenization would be as follows in the screenshot below:
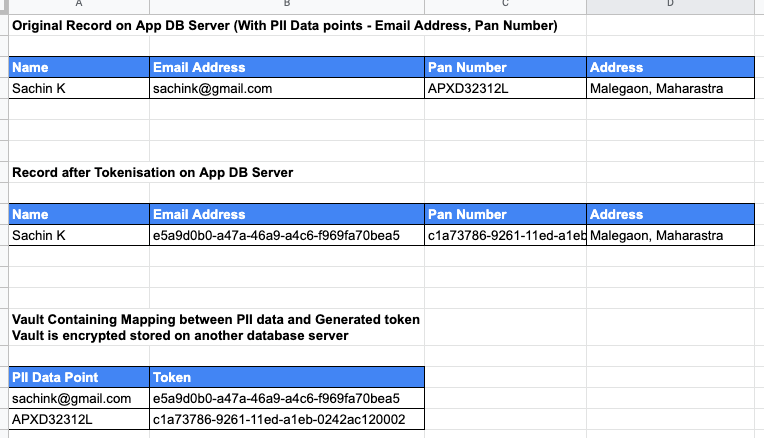
- In the above example, UUID is used as token generation logic.
- Tokenization algorithms can be tweaked in a manner to retain the original format of the data. Generally, this is necessary if PII data points are to be replaced with tokens in legacy applications where DB table field size and validations on a field value in the application code cannot be changed.
- For example, the email address would be replaced with the following token — arfvder@xyzls.com. The original character length of the data field and its format ‘@’ and ‘.com’ have been retained.
2. Encryption
- Fundamental technology to support data confidentiality.
- Uses either Symmetric or Asymmetric encryption to encrypt PII data.
The decision tree below is a useful tool when given a use case in an ecosystem, one has to weigh in a host of factors to choose between tokenization and encryption:
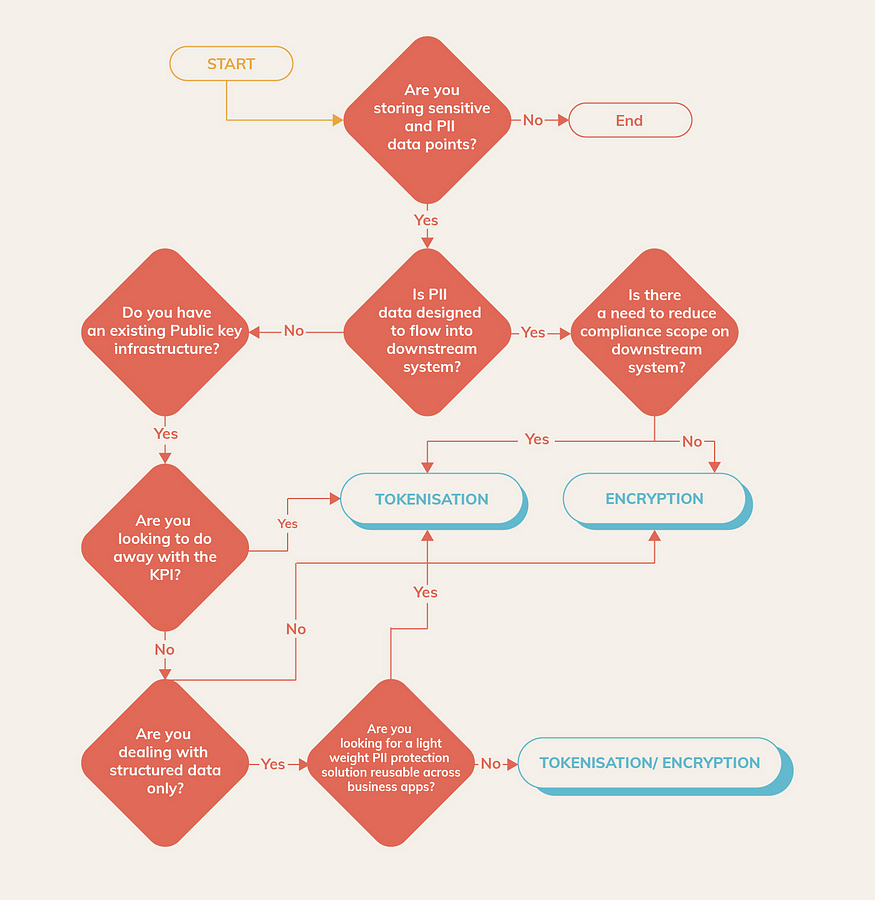
When encryption is used as a PII Data protection technique, there are further considerations about where the encryption is performed. The following are the choices:
2.1 Application-level Data Encryption
- In this approach, data is encrypted and decrypted by a custom application code before sending it to the database server for persistence.
- Integration with Out of Box (OOB) encryption and decryption libraries have to be implemented at an application code level.
- Leaking of encryption and decryption logic into the areas of code which generate reports and other parts of business logic.
2.2 Database-level Data Encryption
- Database providers’ OOB encryption algorithms and functions are used to encrypt and decrypt the data.
- One downside of this approach is that Key rotation has to be managed by the Application code and no OOB support from database provider solutions is available
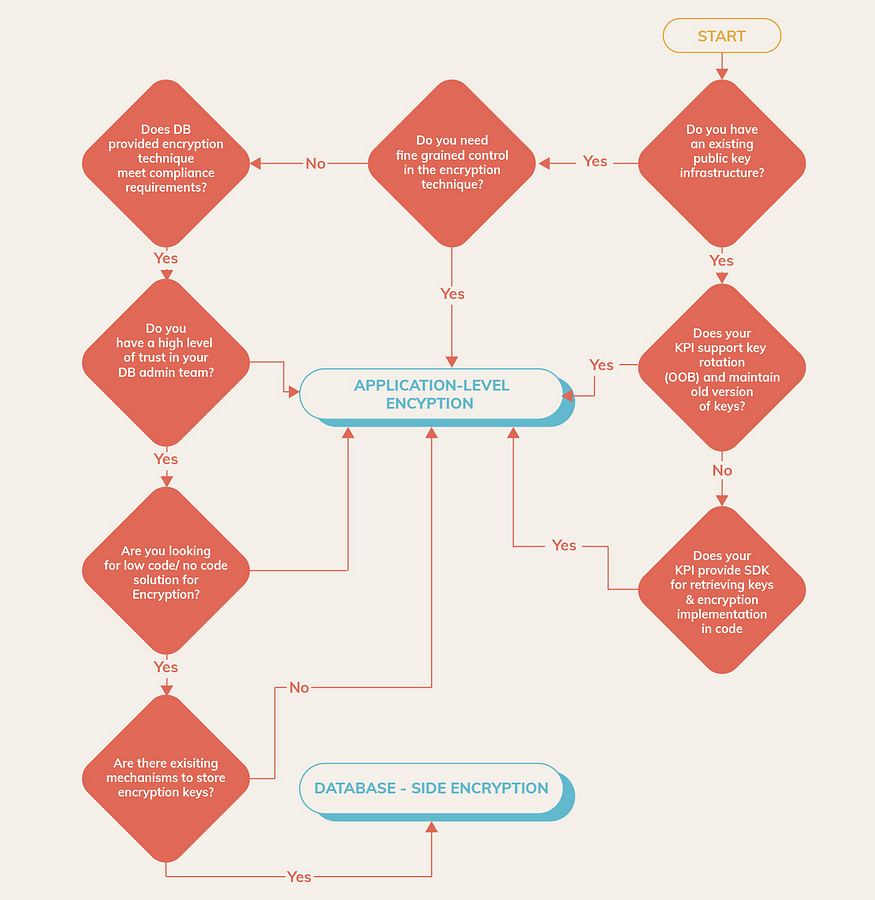
The decision tree below helps make an informed decision regarding the choice of encryption technique best fitted for an ecosystem considering a host of factors ranging from existing Public Key Infrastructure to Encryption Key storage:
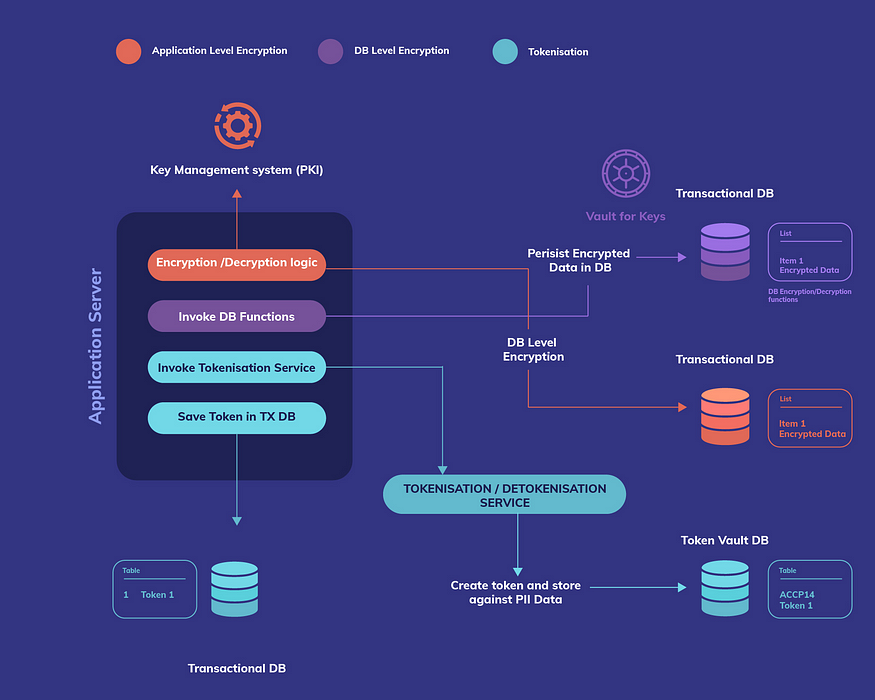
The figure below summarises different types of PII data protection techniques and their key implementation components:
Finally, the choice of encryption technique–symmetric vs asymmetric encryption–is also an important consideration from the perspective of how PII information is encrypted.
2.3 Symmetric Key Encryption
- The same Key is used for encryption and decryption.
- Fast and convenient to set-up.
- Recommended for simple use cases where the producer and consumer of encrypted data are services that are part of the application even though they can be different services (in the context of PII data encryption).
- The key exchange requirement is limited to a few systems (typically 2).
2.4 Asymmetric Key Encryption
- Public-Private Key Pair. The public key can be freely distributed while the private key has to be stored securely.
- Recommended for use cases where there are multiple systems involved in producing and consuming the encrypted data point. Only the public key is shared with data producer services. The private key remains with the service exposing data to consumers.
- The reduced surface area of attack with a private key available with only one service.
- The surface area of attack can be further reduced by having multiple public-private key pairs for different PII data points especially if they reside in different tables or entities. For example, one public-private key pair per table containing PII Data point.
In the context of our system, we made the following design choices:
- Encryption over Tokenization for Credit score records with the following rationale:
- No requirement to push the credit score data to any downstream system like a data warehouse.
- Credit score was to be made available on demand via a separate dedicated service.
- A separate microservice was exposed to share credit score data with other apps and services.
- Credit score records persisted in a separate encrypted database.
- Column-level encryption for credit score details — to prevent system admins and developers access the score details.
2. Tokenization for other PII data points namely PAN number, and email address with the following rationale:
- These PII details acted as customer identity and were required to be synced with the downstream analytics system i.e. data warehouse for analytics purposes.
- Using tokenization reduced the compliance scope on the downstream system.
3. Database-level encryption over application-level encryption with the following rationale:
- Postgres DB was our backend datastore. Postgres provides support for database-level encryption with the pgcrypto module with a range of built-in functions to encrypt data with both symmetric and asymmetric key encryption techniques.
- Spring Boot with Hibernate was our API platform stack. Hibernate provides OOB support for DB-level encryption/decryption in a declarative manner with @ColumTransformer functionality. This was a low-code approach.
- We already had a Key Management system (without key rotation support) with an ansible vault. We did not want to introduce a dependency on external KMS systems provided by cloud providers like AWS KMS or GCP KMS without having a holistic approach to replacing the existing Key Management system across different parts of the platform where encryption was used.
- There was a business need to build something quickly and test it in the pilot and get quick feedback on the product.
- AWS KMS-like solution was an option but customers feared cloud provider lock-in for a such critical business application.
4. Asymmetric Key encryption over Symmetric Key with the following rationale:
- We wanted to keep possibilities open in the future where there would be integration with multiple credit score providers.
- The credit score repository acted as a centralized repository of credit scores for customers. PKI infrastructure gave us the flexibility to distribute the public key to these other producer services while our service maintained the private key to provide decrypted score data to its consumers.
Thus, there are different Data Protection techniques available for sensitive data to be stored in the Datastore, each one applicable in specific scenarios subject to constraints of an ecosystem.
The next part of this blog will cover how Database-side can be leveraged to achieve PII & sensitive data protection with Spring Boot and Hibernate Technologies.

